


خودهمبستگی مکانی (Spatial Autocorrelation) در GeoAI: وقتی «نزدیکی» دردسرساز میشود
نویسنده: فاطمه جعفری نوبخت
اگر از یک متخصص آمار کلاسیک بپرسید که “دشمن شماره یک تو چیست؟”، احتمالاً میگوید: «دادههایی که مستقل نیستند.»
و اگر به یک جغرافیدان بگویید که دادهها باید مستقل باشند، میخندد و قانون اول جغرافیا (والدو توبلر) را به شما یادآوری میکند:
«همه چیز به هم مربوط است، اما چیزهای نزدیکتر، ارتباط بیشتری با هم دارند.»
این وابستگی بین مکانهای نزدیک، خودهمبستگی مکانی نام دارد. در GeoAI، این مفهوم همزمان بزرگترین نقطه قوت (برای درونیابی) و خطرناکترین دام (برای ارزیابی مدل) است.
۱. خودهمبستگی مکانی دقیقاً چیست؟
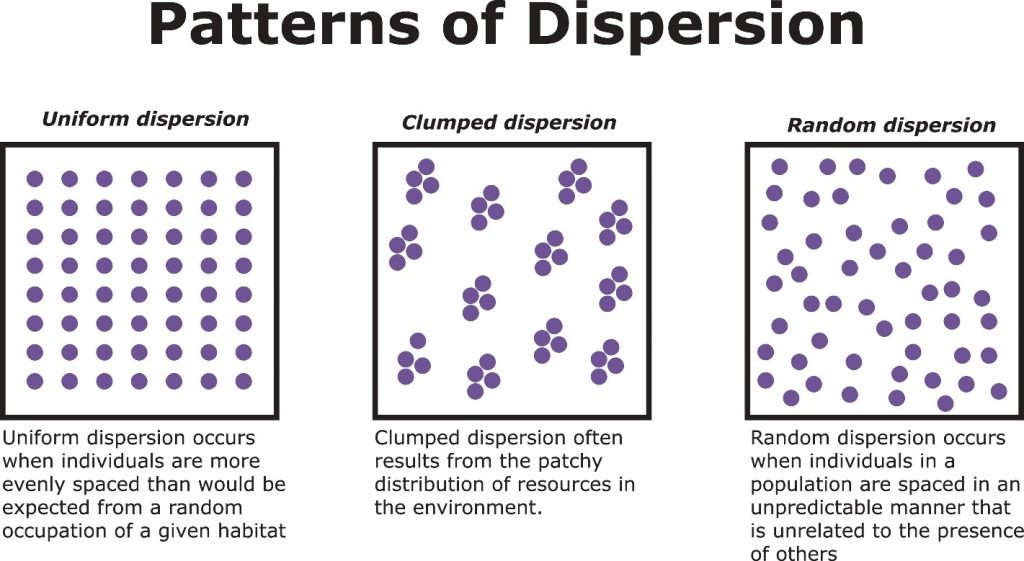
به زبان ساده، یعنی مقدار یک متغیر در نقطه A، اطلاعاتی درباره مقدار آن در نقطه B (که همسایه A است) به ما میدهد.
- خودهمبستگی مثبت (Positive): چیزهای شبیه به هم، کنار هم جمع شدهاند (خوشهای).
- مثال: قیمت مسکن. خانههای گرانقیمت معمولاً در کنار سایر خانههای گرانقیمت در محلههای شمالی شهر قرار دارند.
- خودهمبستگی منفی (Negative): چیزهای ناهمسان کنار هم قرار میگیرند (شطرنجی).
- مثال: رقابت فروشگاهها. معمولاً دو سوپرمارکت بزرگ دقیقاً دیوار به دیوار هم باز نمیشوند، بلکه سعی میکنند فاصله بگیرند.
- عدم خودهمبستگی (Random): هیچ الگویی وجود ندارد.
۲. چرا هوش مصنوعی با این مفهوم مشکل دارد؟ (چالش I.I.D)
اکثر الگوریتمهای استاندارد یادگیری ماشین (مثل Random Forest یا شبکههای عصبی معمولی) بر اساس یک فرض بنیادین بنا شدهاند:
دادهها باید “مستقل و دارای توزیع یکسان” (I.I.D – Independent and Identically Distributed) باشند.
خودهمبستگی مکانی دقیقاً همین فرض «استقلال» را نقض میکند.
- مثال: فرض کنید میخواهیم قیمت خانه را پیشبینی کنیم. اگر خانه شماره ۱ در دیتای آموزش (Train) باشد و خانه شماره ۲ (که دیوار به دیوار آن است) در دیتای تست (Test) باشد، مدل عملاً جواب را میداند! چون قیمت خانه ۲ تقریباً همان قیمت خانه ۱ است.
- نتیجه: مدل در مرحله آموزش و تست دقت ۹۹٪ نشان میدهد، اما وقتی آن را برای یک شهر جدید به کار میبرید، دقت به ۵۰٪ سقوط میکند. این پدیده نشت داده مکانی (Spatial Data Leakage) نام دارد.
۳. سنجش خودهمبستگی: شاخص Moran’s I
قبل از اینکه دادهها را به مدل GeoAI بدهیم، باید بدانیم چقدر به هم وابستهاند. معروفترین ابزار، شاخص Moran’s I است.
I = \frac{N}{\sum_i \sum_j w_{ij}} \frac{\sum_i \sum_j w_{ij}(x_i – \bar{x})(x_j – \bar{x})}{\sum_i (x_i – \bar{x})^2}
این شاخص عددی بین -1 تا +1 است:
- +1: همبستگی مثبت کامل (خوشهای شدید).
- 0: تصادفی (مناسب برای آمار کلاسیک).
- -1: همبستگی منفی کامل (پراکندگی منظم).
اگر Moran’s I دادههای شما بالا باشد (مثلاً ۰.۸)، نباید از روشهای تقسیم داده معمولی (Random Split) استفاده کنید.
۴. چگونه خودهمبستگی را در GeoAI مدیریت کنیم؟
ما دو راه داریم: یا با آن بجنگیم، یا آن را در آغوش بگیریم!
راهکار اول: مبارزه (برای ارزیابی صحیح)
برای جلوگیری از نشت داده و دروغ گفتن مدل به خودش، باید نحوه تقسیم دادهها را عوض کنیم:
- Spatial Cross-Validation: به جای انتخاب تصادفی نقاط، نقشه را به بلوکهای بزرگ (مثلاً ۵ کیلومتر در ۵ کیلومتر) تقسیم کنید. تمام نقاط داخل بلوک A را برای آموزش و تمام نقاط داخل بلوک B را برای تست بردارید. با این کار، بین دادههای آموزش و تست یک «منطقه حائل» (Buffer) ایجاد میشود و مدل مجبور میشود قوانین کلی را یاد بگیرد، نه اینکه صرفاً همسایهها را حفظ کند.
راهکار دوم: پذیرش (برای بهبود مدل)
میتوانیم خودهمبستگی را به عنوان یک ویژگی (Feature) به مدل بدهیم:
- اضافه کردن تاخیر مکانی (Spatial Lag):
یک ستون جدید به دادهها اضافه کنید که «میانگین مقدار همسایگان» است.
- ورودی: ویژگیهای خانه + میانگین قیمت ۵ خانه اطراف.
- نتیجه: مدل یاد میگیرد که قیمت خانه فقط تابع مساحت نیست، بلکه تابع محله هم هست.
- استفاده از شبکههای عصبی گراف (GNN):
این مدلها ذاتاً برای مدیریت وابستگی ساخته شدهاند. در GNN، هر مکان یک «گره» (Node) است و همسایگیها «یال» (Edge) هستند. اطلاعات بین همسایهها جریان مییابد و خودهمبستگی مکانی به طور طبیعی مدلسازی میشود.
۵. باقیماندهها (Residuals) نباید خودهمبستگی داشته باشند
نکته طلایی برای حرفهایها:
بعد از اینکه مدل GeoAI شما پیشبینی کرد، باید خطاهای مدل (پیشبینی – واقعیت) را روی نقشه رسم کنید.
- اگر خطاها تصادفی پخش شده باشند (Moran’s I خطاها نزدیک صفر باشد)، یعنی مدل شما عالی کار کرده و تمام الگوهای مکانی را یاد گرفته است.
- اگر خطاها خوشهای باشند (مثلاً مدل در تمام شمال شهر قیمت را کمتر تخمین زده)، یعنی هنوز یک عامل مکانی وجود دارد که مدل آن را کشف نکرده است (خودهمبستگی مکانی در باقیماندهها).
6. نتیجهگیری
خودهمبستگی مکانی، روحِ دادههای جغرافیایی است. بدون آن، نقشهها فقط مجموعهای از نقاط تصادفی و بیمعنی هستند.
در GeoAI، هنر ما این است که:
- در مرحله آموزش، از ویژگیهای همسایگی (Spatial Lag) استفاده کنیم تا مدل هوشمندتر شود.
- در مرحله تست، با استفاده از Spatial CV، ارتباط همسایگی را قطع کنیم تا مدل را در سختترین شرایط بیازماییم.






