شبکه عصبی کانولوشنی (CNN): چشمهای بینای هوش مصنوعی
نویسنده: فاطمه جعفری نوبخت
زمانی که ما به تصویر یک “گربه” نگاه میکنیم، مغز ما فوراً آن را تشخیص میدهد. اما برای کامپیوتر، آن تصویر فقط آرایهای از اعداد (پیکسلها) است. شبکه عصبی کانولوشنی یا Convolutional Neural Network (به اختصار CNN یا ConvNet)، معماری خاصی از یادگیری عمیق (Deep Learning) است که دقیقاً برای حل این مشکل طراحی شده است: درک محتوای تصاویر.
امروزه CNNها ستون فقرات بینایی ماشین (Computer Vision) هستند؛ از تشخیص چهره در موبایل شما گرفته تا تحلیل تصاویر ماهوارهای در GIS و خودروهای خودران.
1- چرا شبکههای عصبی معمولی کافی نبودند؟
در شبکههای عصبی کلاسیک (MLP)، ورودیها باید به صورت یک لیست خطی (Vector) باشند. اگر بخواهید یک تصویر کوچک (مثلاً ۱۰۰×۱۰۰ پیکسل) را به MLP بدهید، باید ساختار دو بعدی آن را خراب کنید و ۱۰,۰۰۰ ورودی بسازید.
این کار دو مشکل ایجاد میکند:
- از بین رفتن روابط مکانی: در تصاویر، پیکسلهای همسایه به هم مرتبط هستند (مثلاً پیکسلهای یک لبه). با خطی کردن تصویر، این اطلاعات حیاتی از بین میرود.
- حجم محاسباتی انفجاری: برای تصاویر بزرگ، تعداد وزنهای شبکه غیرقابل مدیریت میشود.
راه حل CNN: این شبکه ورودی را به صورت ماتریس (دو بعدی یا سه بعدی) میپذیرد و روابط مکانی و هندسی را حفظ میکند.
2- معماری و ساختار CNN
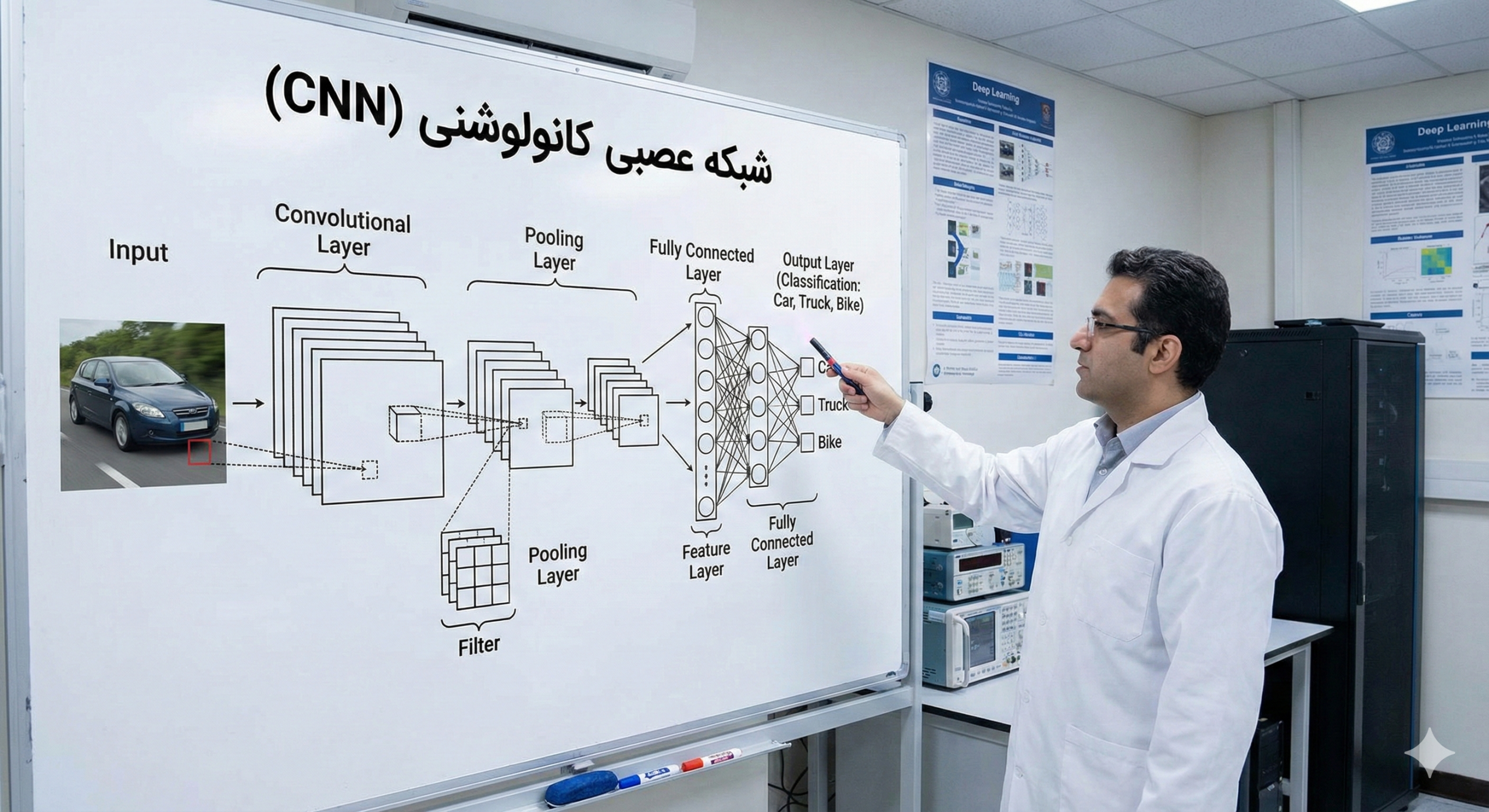
یک شبکه CNN شبیه به خط تولید یک کارخانه عمل میکند که در آن تصویر خام وارد شده و مرحله به مرحله ویژگیهای آن استخراج میشود تا به تشخیص نهایی برسد. این شبکه از سه نوع لایه اصلی تشکیل شده است:
1-2- لایه کانولوشن (Convolutional Layer): استخراج ویژگی
این لایه قلب تپنده شبکه است. در اینجا، یک پنجره کوچک به نام فیلتر (Filter) یا کرنل (Kernel) روی تصویر حرکت میکند.
- عملکرد: تصور کنید یک چراغقوه کوچک (فیلتر) را روی یک تصویر بزرگ حرکت میدهید. در هر توقف، فیلتر اعداد تصویر را در اعداد خودش ضرب میکند.
- هدف: هر فیلتر مسئول پیدا کردن یک ویژگی خاص است. یک فیلتر ممکن است فقط “خطوط عمودی” را ببیند، دیگری “خطوط افقی” و دیگری “تغییر رنگ” را.
- خروجی: نتیجه این عملیات، یک ماتریس جدید به نام نقشه ویژگی (Feature Map) است که نشان میدهد آن ویژگی خاص در کجای تصویر وجود دارد.
Output(i,j) = (Input * Kernel)(i,j) = \sum \sum I(m,n) \cdot K(i-m, j-n)
2-2- لایه ادغام یا استخر (Pooling Layer): خلاصهسازی
پس از استخراج ویژگیها، حجم دادهها معمولاً هنوز زیاد است. لایه Pooling ابعاد تصویر را کاهش میدهد تا محاسبات سبکتر شود و شبکه به تغییرات جزئی و نویز حساس نباشد (Invariance).
- Max Pooling: رایجترین روش است. پنجرهای روی تصویر حرکت میکند و فقط بزرگترین عدد (مهمترین ویژگی) را نگه میدارد و بقیه را دور میریزد.
- مثال: یک ماتریس ۴×۴ را به ۲×۲ تبدیل میکند، اما قویترین سیگنالها را حفظ میکند.
3-2- لایه تماممتصل (Fully Connected Layer): تصمیمگیری
پس از تکرار چندین باره لایههای کانولوشن و پولینگ، تصویر اولیه به مجموعهای از ویژگیهای انتزاعی و سطح بالا تبدیل شده است (مثلاً: اینجا گوش است، اینجا چشم است).
در این مرحله نهایی، دادهها “مسطح” (Flatten) میشوند و به یک شبکه عصبی کلاسیک داده میشوند تا بر اساس ویژگیهای کشف شده، تصمیم نهایی را بگیرد (مثلاً: این تصویر ۹۵٪ احتمال دارد گربه باشد).
3- مفاهیم کلیدی و اصطلاحات فنی
- گام (Stride): میزان پرش فیلتر روی تصویر. اگر Stride=1 باشد، فیلتر پیکسل به پیکسل جلو میرود. اگر Stride=2 باشد، دوتا دوتا میپرد (که باعث کوچک شدن خروجی میشود).
- پدینگ (Padding): وقتی فیلتر روی لبههای تصویر اعمال میشود، ابعاد تصویر کوچک میشود. برای جلوگیری از این اتفاق، دور تصویر را با صفر پر میکنند (Zero Padding) تا سایز تصویر حفظ شود.
- تابع فعالساز (ReLU): پس از هر کانولوشن، از تابع ReLU استفاده میشود تا مقادیر منفی را صفر کند. این کار باعث میشود شبکه “غیرخطی” شود و بتواند الگوهای پیچیده را یاد بگیرد.
4- سلسله مراتب یادگیری (Hierarchy of Features)
قدرت جادویی CNN در لایهبندی آن است:
- لایههای ابتدایی: خطوط ساده، لبهها و رنگها را میبینند.
- لایههای میانی: ترکیب خطوط را میبینند (مثل دایره، گوشه، بافت آجر).
- لایههای پایانی: اشیاء کامل را تشخیص میدهند (مثل صورت انسان، چرخ ماشین، پنجره ساختمان).
5-کاربرد CNN در GIS و سنجش از دور
از آنجا که دادههای رستری (تصاویر ماهوارهای و هوایی) دقیقاً ماتریس هستند، CNN بهترین ابزار برای تحلیل آنهاست:
- طبقهبندی کاربری اراضی (LULC): تشخیص اینکه هر پیکسل تصویر متعلق به جنگل، آب، شهر یا کشاورزی است.
- تشخیص اشیاء (Object Detection): پیدا کردن و شمارش خودکار عوارض خاص مثل ساختمانها، خودروها، مخازن نفت یا درختان نخل در تصاویر ماهوارهای.
- استخراج جادهها: تبدیل خودکار عکس هوایی به خطوط برداری (Vector) جادهها برای آپدیت نقشهها.
6- نتیجهگیری
شبکه عصبی کانولوشنی (CNN) انقلابی در نحوه تعامل کامپیوتر با دنیای بصری ایجاد کرده است. این شبکه با الهام از کورتکس بینایی مغز انسان، یاد میگیرد که الگوها را از ساده به پیچیده شناسایی کند. برای یک متخصص GIS، تسلط بر مفهوم CNN کلید ورود به دنیای GeoAI و تحلیلهای خودکار تصاویر ماهوارهای است.
درباره نویسنده:
فاطمه جعفری نوبخت، متخصص برجسته و پژوهشگر حوزه مهندسی محیط زیست، با رویکردی نوین دانش کلاسیک این رشته را با فناوریهای پیشرفته هوش مصنوعی تلفیق کرده و به عنوان پیشگام در زمینه هوش مصنوعی مکانی (GeoAI) شناخته میشود. وی با تکیه بر مدرک کارشناسی ارشد مهندسی محیط زیست و درک عمیق از اکوسیستمها، تخصص خود را فراتر از روشهای سنتی گسترش داده و با ورود به دنیای دادهها، فعالیتهای حرفهای خود را بر کاربرد هوش مصنوعی در علوم محیط زیست متمرکز کرده است. او هماکنون به عنوان مشاور ارشد علوم مکانی در محیط زیست و منابع طبیعی، با استفاده از الگوریتمهای پیشرفته در پی راهکارهایی برای پایش دقیق، پیشبینی تغییرات اقلیمی و مدیریت بهینه منابع است. فاطمه جعفری با باور بنیادین به اینکه «مهمترین توجه انسانها باید به مقوله محیط زیست باشد»، تکنولوژی را ابزاری قدرتمند برای نجات زمین میداند و علاوه بر پروژههای استراتژیک، با برگزاری مستمر کارگاههای آموزشی در زمینه علوم مکانی و زمین، مشتاقانه به انتقال دانش و تربیت نسلی متخصص برای حفاظت از آینده محیط زیست میپردازد.