کمبرازش (Underfitting): وقتی مدل “ضعیف(ساده)” است
نویسنده: فاطمه جعفری نوبخت
در یادگیری ماشین، ما همیشه نگرانیم که مدلمان بیش از حد روی جزئیات وسواس به خرج دهد و دادهها را حفظ کند (Overfitting). اما سمت دیگر این بام، پرتگاه دیگری وجود دارد که به همان اندازه خطرناک است: کمبرازش یا Underfitting.
اگر بیشبرازش را به دانشآموزی تشبیه کنیم که پاسخهای تستهای سالهای قبل را حفظ کرده اما مفهوم را نفهمیده، کمبرازش دانشآموزی است که اصلاً درس را یاد نگرفته و حتی پاسخ سوالات سادهی کتاب را هم غلط مینویسد.
در این حالت، مدل آنقدر ساده و سطحی است که نمیتواند الگوهای موجود در دادهها را درک کند.
۱. تعریف فنی: بایاس بالا (High Bias)
برای درک عمیق کمبرازش، باید با مفهوم بایاس (Bias) یا سوگیری در آمار آشنا باشید.
- بایاس: خطای ناشی از فرضیات غلط و سادهانگارانهی مدل.
- کمبرازش = بایاس بالا.
تصور کنید دادههای شما روی نمودار به شکل یک منحنی (سهمی) هستند. اگر شما سعی کنید با یک خط راست از میان این دادهها عبور کنید، هر کاری هم بکنید، خط راست نمیتواند انحنا را پوشش دهد. این ناتوانی ذاتی مدل در تطبیق با پیچیدگی داده، همان کمبرازش است.
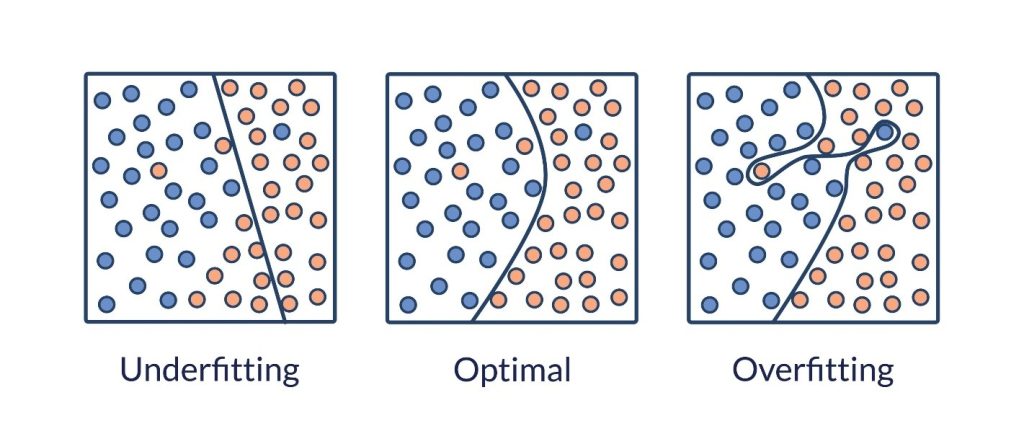
۲. علائم و تشخیص
چگونه بفهمیم مدل ما دچار کمبرازش شده است؟ تشخیص آن معمولاً سادهتر از بیشبرازش است.
در فرآیند آموزش و اعتبارسنجی (که در مقاله قبلی بررسی کردیم):
- خطای آموزش (Training Error) بالا است: مدل حتی روی دادههایی که دیده است هم ضعیف عمل میکند.
- خطای اعتبارسنجی (Validation Error) بالا است: مدل روی دادههای جدید هم ضعیف است.
- نزدیکی خطاها: برخلاف بیشبرازش (که خطای آموزش کم و خطای تست زیاد است)، در کمبرازش هر دو خطا زیاد هستند و به هم نزدیکاند.
خلاصه: اگر مدل شما “خنگ” به نظر میرسد و هیچ دقتی ندارد، احتمالاً دچار Underfitting شده است.
۳. دلایل اصلی وقوع
چرا یک مدل نمیتواند یاد بگیرد؟
الف) مدل خیلی ساده است
رایجترین دلیل. مثلاً استفاده از “رگرسیون خطی” برای دادههایی که رابطه “غیرخطی” و پیچیده دارند. یا استفاده از یک شبکه عصبی با لایههای خیلی کم (Shallow Network) برای تشخیص تصاویر پیچیده.
ب) کمبود ویژگی (Lack of Features)
شما اطلاعات کافی به مدل نمیدهید.
- مثال: میخواهید قیمت خانه را پیشبینی کنید، اما فقط “متراژ” را به مدل میدهید و “محل قرارگیری” (که مهمترین فاکتور است) را حذف میکنید. مدل با یک ویژگی نمیتواند قیمت را درست حدس بزند.
ج) تنظیم بیش از حد (Over-Regularization)
تکنیکهای Regularization (مثل L1/L2 یا Dropout) برای جلوگیری از بیشبرازش استفاده میشوند. اما اگر در استفاده از آنها زیادهروی کنید (مثلاً ضریب جریمه را خیلی بالا ببرید)، مدل آنقدر محدود میشود که حتی الگوهای ساده را هم نمیتواند یاد بگیرد. مثل بستن دست و پای یک نقاش و انتظار کشیدن یک شاهکار.
۴. راهکارهای درمان (چگونه کمبرازش را رفع کنیم؟)
درمان کمبرازش دقیقاً برعکس درمان بیشبرازش است. هدف ما افزایش پیچیدگی و آزادی عمل مدل است.
۱. مدل را پیچیدهتر کنید
- اگر از رگرسیون خطی استفاده میکنید، به سراغ رگرسیون چندجملهای (Polynomial) یا درختهای تصمیم بروید.
- اگر از شبکه عصبی استفاده میکنید، تعداد لایهها یا تعداد نورونهای هر لایه را افزایش دهید.
۲. مهندسی ویژگی (Feature Engineering)
ویژگیهای جدید خلق کنید.
- در مثال قیمت خانه، ویژگیهای جدیدی مثل “فاصله تا مرکز شهر”، “سن بنا” و “تعداد اتاق” را اضافه کنید.
- ویژگیهای ترکیبی بسازید (مثلاً حاصلضرب طول در عرض).
۳. کاهش سختگیری (Less Regularization)
پارامترهای تنظیمکننده را شل کنید.
- در رگرسیون Lasso یا Ridge، ضریب Lambda یا Alpha را کاهش دهید.
- در شبکههای عصبی، نرخ Dropout را کم کنید.
۴. آموزش طولانیتر (More Epochs)
گاهی مدل پتانسیل یادگیری دارد، اما شما زود آموزش را قطع کردهاید. اجازه دهید مدل بیشتر دادهها را ببیند تا خطا (Loss) کاهش یابد.
۵. مثال کاربردی در GIS و محیط زیست
فرض کنید میخواهید مدلی بسازید که میزان فرسایش خاک در یک حوضه آبریز را پیشبینی کند.
- سناریوی کمبرازش:
شما فقط از یک لایه اطلاعاتی یعنی “شیب زمین” استفاده میکنید و مدل شما یک رگرسیون خطی ساده است.
- نتیجه: مدل پیشبینی میکند که “هر جا شیب بیشتر است، فرسایش بیشتر است”. اما در واقعیت، جاهایی وجود دارد که شیب زیاد است اما پوشش گیاهی متراکم مانع فرسایش میشود. مدل شما چون ساده است و داده کافی ندارد، خطای زیادی دارد (Underfitting).
- راه حل:
شما باید:
- مدل را به “Random Forest” (که غیرخطی است) ارتقا دهید.
- لایههای جدید شامل “پوشش گیاهی (NDVI)”، “جنس خاک” و “میزان بارندگی” را به عنوان ویژگی اضافه کنید.
حالا مدل میتواند روابط پیچیده را یاد بگیرد.
6. نتیجهگیری
کمبرازش یعنی ناتوانی در رسیدن به حداقلهای مطلوب. در حالی که اکثر مقالات علمی روی خطرات بیشبرازش (Overfitting) تمرکز دارند، در دنیای واقعی و شروع پروژهها، اغلب با کمبرازش روبرو میشویم (زمانی که هنوز ویژگیهای مناسب را پیدا نکردهایم).
هدف نهایی در یادگیری ماشین، پیدا کردن نقطه شیرین (Sweet Spot) است: جایی بین سادگی بیش از حد (کمبرازش) و پیچیدگی بیش از حد (بیشبرازش).