


بخشبندی معنایی (Semantic Segmentation): دیدن جهان، پیکسل به پیکسل
نویسنده: فاطمه جعفری نوبخت
1. مقدمه
اگر “تشخیص شیء” (Object Detection) را به کشیدن یک مربع دور یک گربه در تصویر تشبیه کنیم، بخشبندی معنایی (Semantic Segmentation) به معنای رنگآمیزی دقیق تکتک پیکسلهایی است که گربه را تشکیل میدهند.
در این روش، هدف ما فقط دانستن اینکه “چه چیزی” در تصویر است یا “کجاست” نیست؛ بلکه میخواهیم بدانیم مرز دقیق هر شیء کجاست. در واقع، بخشبندی معنایی فرآیند اختصاص دادن یک برچسب (مانند آسمان، زمین، ماشین، انسان) به تکتک پیکسلهای یک تصویر است.
2. تفاوت با سایر تکنیکهای بینایی
برای درک بهتر، باید جایگاه این تکنیک را در میان سایر روشها بشناسیم:
- دستهبندی (Classification): فقط میگوید “در این تصویر یک بادکنک وجود دارد”.
- تشخیص شیء (Object Detection): میگوید “بادکنک در این کادر مستطیلی قرار دارد”.
- بخشبندی معنایی (Semantic Segmentation): تمام پیکسلهای مربوط به بادکنک را جدا میکند. (نکته: اگر دو بادکنک کنار هم باشند، همه را یکپارچه “بادکنک” میداند و آنها را از هم تفکیک نمیکند).
- بخشبندی نمونهای (Instance Segmentation): دقیقترین حالت؛ هم پیکسلها را جدا میکند و هم میفهمد که “بادکنک ۱” از “بادکنک ۲” جداست.
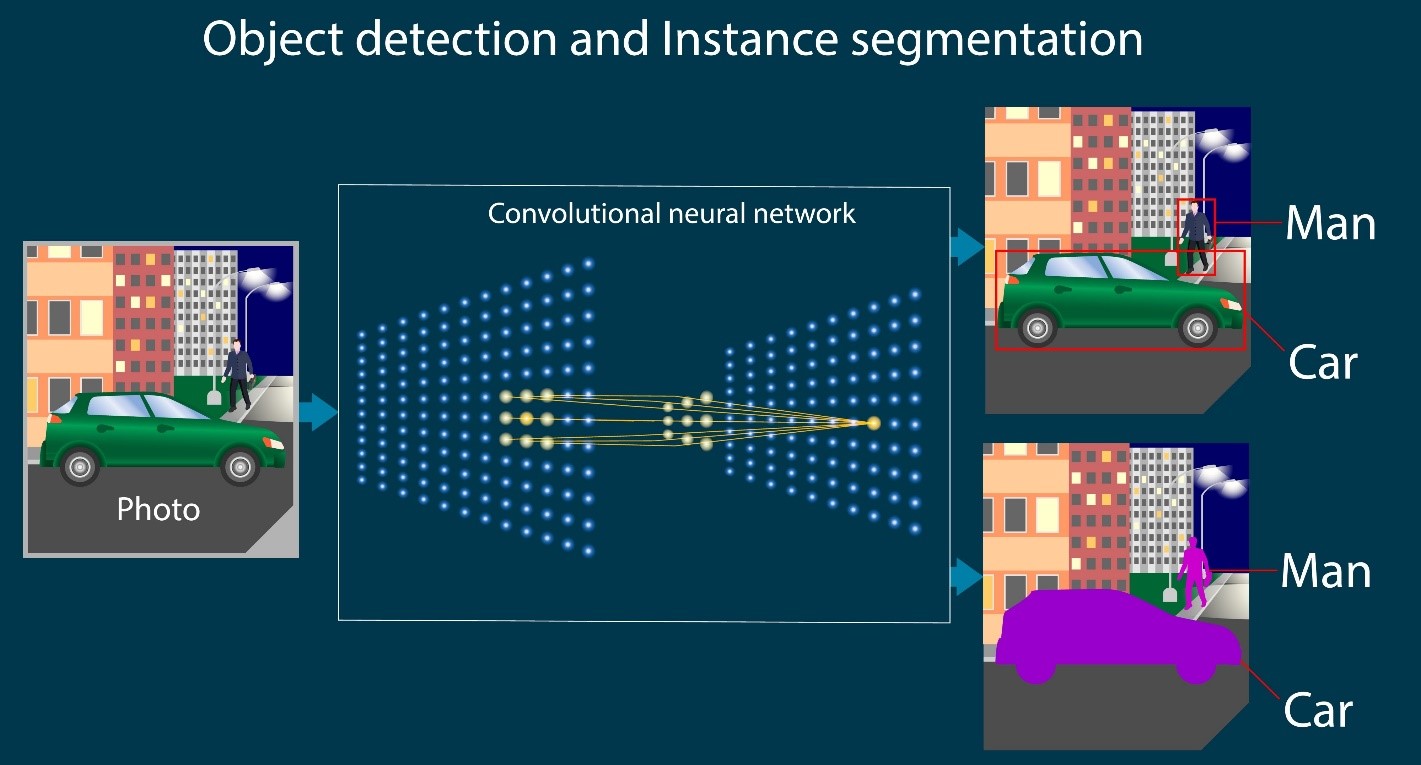
3. معماریهای رایج: ساختار “کدگذار-کدگشا”
اکثر مدلهای بخشبندی معنایی مدرن از ساختاری به نام Encoder-Decoder (کدگذار-کدگشا) پیروی میکنند:
الف) کدگذار (Encoder): بخشِ کوچککننده
این بخش معمولاً یک شبکه CNN استاندارد (مانند ResNet یا VGG) است که نقش استخراج ویژگی را دارد. همانطور که تصویر در لایهها جلو میرود، ابعاد آن کوچک میشود (Downsampling) اما عمق ویژگیها و مفاهیم انتزاعی آن افزایش مییابد. در اینجا جزئیات مکانی (مکان دقیق پیکسلها) فدای درک محتوایی میشود.
ب) کدگشا (Decoder): بخشِ بزرگکننده
این بخش وظیفه دارد ویژگیهای استخراج شده را دوباره به ابعاد اصلی تصویر بازگرداند (Upsampling). هدف این است که مکان دقیق اشیاء بازیابی شود تا بتوانیم یک نقشه پیکسلی (Mask) تولید کنیم که هماندازه تصویر اصلی است.
ج) معماریهای مشهور
- U-Net: مشهورترین معماری (به شکل حرف U). ویژگی منحصربهفرد آن اتصالات پرشی (Skip Connections) است که اطلاعات مکانی دقیق را از لایههای ابتدایی (Encoder) مستقیم به لایههای انتهایی (Decoder) منتقل میکند تا دقت لبهها حفظ شود.
- FCN (Fully Convolutional Networks): اولین مدلی که لایههای متراکم (Dense) را حذف کرد تا بتواند تصاویر با هر اندازهای را ورودی بگیرد.
- DeepLab: توسعهیافته توسط گوگل. از تکنیکی به نام Dilated Convolution (کانولوشن متسع) استفاده میکند تا میدان دید (Receptive Field) شبکه را بدون کاهش ابعاد تصویر، گسترش دهد.
4. معیارهای ارزیابی: چگونه دقت را بسنجیم؟
در اینجا “دقت” (Accuracy) معمولی معیار خوبی نیست، زیرا اکثر پیکسلهای تصویر ممکن است پسزمینه باشند.
- IoU (اشتراک بر اجتماع): رایجترین معیار. نسبت مساحت ناحیه مشترک بین پیشبینی و واقعیت، به مساحت کل اجتماع آنها.
IoU = \frac{\text{Area of Overlap}}{\text{Area of Union}}
- Dice Coefficient: معیاری مشابه IoU که معمولاً در پردازش تصاویر پزشکی محبوبتر است (چون به عدم تعادل دادهها حساسیت کمتری دارد).
5. کاربردهای حیاتی
بخشبندی معنایی چشمانِ دقیق هوش مصنوعی در صنایع مختلف است:
- خودروهای خودران: ماشین باید بداند دقیقاً کجا جاده آسفالت تمام میشود و پیادهرو شروع میشود. یک مستطیل تقریبی کافی نیست؛ سانتیمترها حیاتی هستند.
- تصاویر ماهوارهای و GIS: برای نقشهبرداری کاربری اراضی (Land Cover Mapping). تشخیص دقیق مرز جنگلها، منابع آب، و گسترش شهری از روی تصاویر هوایی.
- پزشکی: جداسازی دقیق بافت تومور از بافت سالم در اسکنهای MRI برای جراحیهای دقیق یا پرتودرمانی.
- کشاورزی دقیق: تشخیص دقیق علفهای هرز در میان محصولات برای سمپاشی نقطهای (به جای سمپاشی کل مزرعه).
6. چالشها
- هزینه برچسبگذاری: برای آموزش این مدلها، انسانها باید هزاران تصویر را پیکسل به پیکسل رنگآمیزی کنند که بسیار زمانبر و پرهزینه است.
- اشیاء کوچک: این مدلها معمولاً در تشخیص اشیاء بسیار کوچک در تصویر (مثلاً یک ماشین در تصویر ماهوارهای وسیع) دچار مشکل میشوند.
7. نتیجهگیری
بخشبندی معنایی پل نهایی بین بینایی ماشین و درک کامل محیط است. در حالی که تشخیص شیء به ما میگوید “چه چیزی” وجود دارد، بخشبندی معنایی به ما میگوید آن شیء “چگونه” در فضا گسترش یافته است. با پیشرفت معماریهایی مانند Vision Transformers (ViT)، دقت این مدلها همچنان در حال افزایش است.






