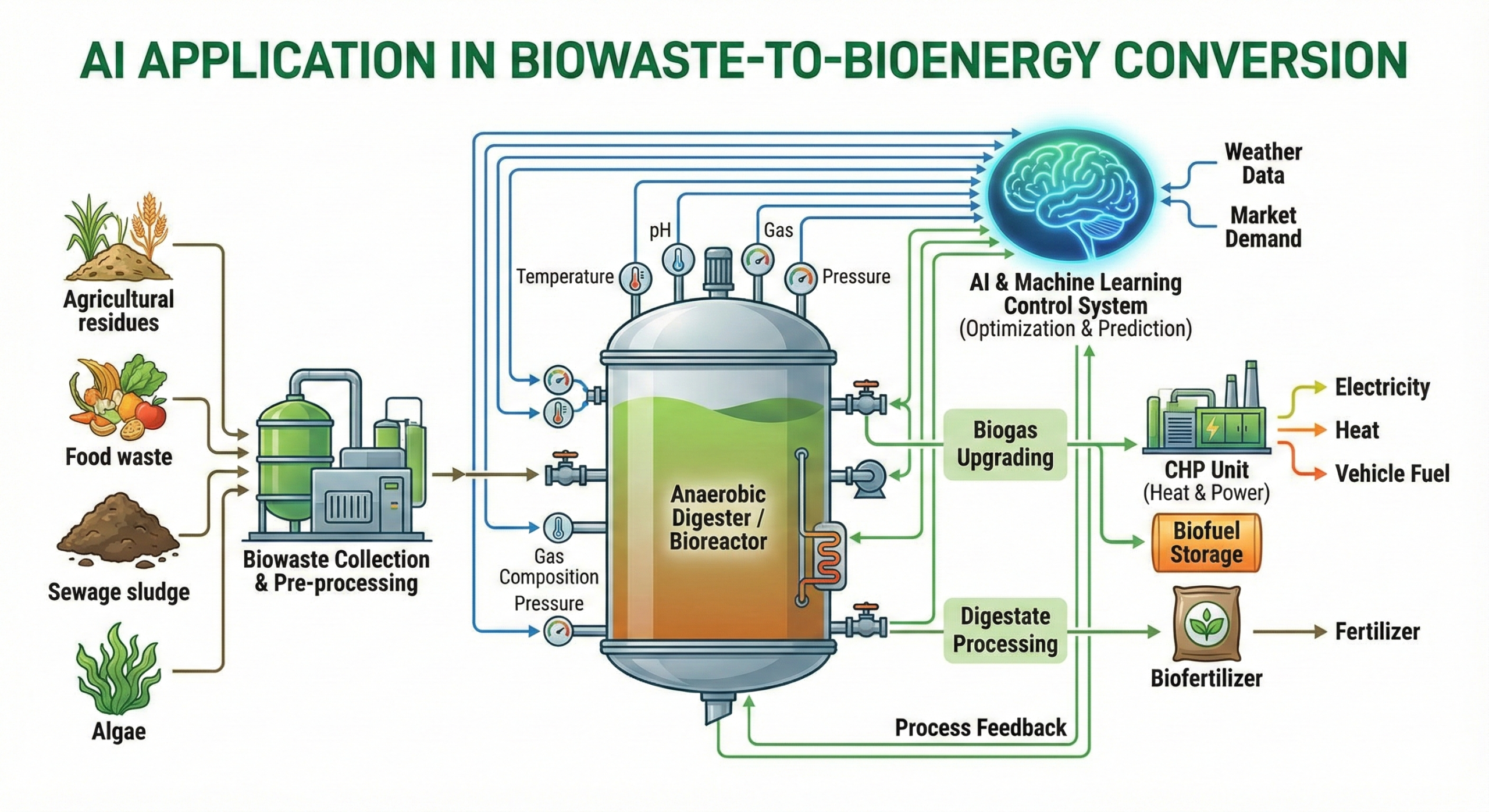
دادههای آموزشی (Training Data): سوخت موتور هوش مصنوعی
نویسنده: فاطمه جعفری نوبخت
1. مقدمه
اگر الگوریتمهای هوش مصنوعی را به یک “موتور” تشبیه کنیم، دادههای آموزشی حکم “سوخت” آن را دارند. بهترین و پیشرفتهترین موتور فراری هم بدون سوخت باکیفیت حرکت نخواهد کرد.
در یادگیری ماشین، مدلها کدنویسی نمیشوند که دقیقاً چه کاری انجام دهند (مثل برنامهنویسی سنتی)؛ بلکه آنها با دیدن مثالها “یاد میگیرند”. این مجموعه مثالها همان دادههای آموزشی هستند. کیفیت، کمیت و تنوع این دادههاست که تعیین میکند آیا هوش مصنوعی شما یک نابغه خواهد شد یا یک سیستم پر از خطا.
2. داده آموزشی دقیقاً چیست؟
داده آموزشی مجموعهای از اطلاعات (متن، تصویر، صدا، عدد) است که برای آموزش دادن به مدل استفاده میشود تا بتواند الگوها را شناسایی کند.
برای مثال، اگر بخواهیم مدلی بسازیم که “ایمیلهای اسپم” را تشخیص دهد، داده آموزشی ما شامل هزاران ایمیل است که قبلاً توسط انسانها برچسب خوردهاند:
- ایمیل ۱: “برنده قرعهکشی شدید…” -> برچسب: اسپم
- ایمیل ۲: “جلسه فردا ساعت ۱۰…” -> برچسب: غیر اسپم
مدل با دیدن این زوجهای (ورودی + خروجی)، یاد میگیرد که چه کلماتی نشانه اسپم بودن هستند.
3. تثلیث مقدس دادهها: Train، Validation و Test
در یک پروژه استاندارد، همه دادهها برای آموزش استفاده نمیشوند. ما معمولاً دادهها را به سه بخش تقسیم میکنیم:
- دادههای آموزشی (Training Set) – حدود ۷۰٪ تا ۸۰٪:
- این دادهها مستقیماً به مدل خورانده میشوند. مدل وزنهای خود را با این دادهها تنظیم میکند (مثل کتابهای درسی که دانشآموز در طول ترم میخواند).
- دادههای اعتبارسنجی (Validation Set) – حدود ۱۰٪ تا ۱۵٪:
- در حین آموزش، هر چند وقت یکبار مدل را با این دادهها چک میکنیم تا ببینیم آیا مسیر را درست میرود یا خیر. از این دادهها برای تنظیم پارامترهای مدل (Hyperparameters) استفاده میشود (مثل کوییزهای کلاسی).
- دادههای تست (Test Set) – حدود ۱۰٪ تا ۱۵٪:
- این دادهها تا پایان کار کاملاً مخفی میمانند. وقتی مدل نهایی شد، برای سنجش عملکرد واقعی آن از این دادهها استفاده میکنیم (مثل امتحان نهایی). اگر مدل این دادهها را قبلاً دیده باشد، تقلب محسوب میشود!
4. اصل GIGO: زباله در برابر طلا
یک قانون طلایی در علوم داده وجود دارد: Garbage In, Garbage Out (GIGO).
یعنی اگر “زباله” وارد سیستم کنید، خروجی هم “زباله” خواهد بود، حتی اگر از پیشرفتهترین الگوریتم جهان استفاده کنید.
ویژگیهای داده آموزشی باکیفیت:
- مرتبط بودن: برای تشخیص سرطان ریه، دادههای شکستگی استخوان به درد نمیخورد.
- جامعیت: دادهها باید تمام حالات ممکن را پوشش دهند. (مثلاً برای ماشین خودران، فقط دادههای روز آفتابی کافی نیست؛ دادههای شب، باران و برف هم لازم است).
- ثبات (Consistency): برچسبها نباید متناقض باشند (نمیشود یک عکس گربه را یک بار “گربه” و بار دیگر “حیوان” نامید).
- تمیزی: دادهها نباید نویز، مقادیر گمشده یا تکراری داشته باشند.
5. انواع دادههای آموزشی
بسته به نوع یادگیری، دادهها متفاوتند:
الف) دادههای برچسبدار (Labeled Data)
مخصوص یادگیری نظارتشده (Supervised Learning).
- انسانها (Annotators) روی دادهها کار کرده و جواب درست را مشخص کردهاند.
- مثال: کشیدن کادر دور ماشینها در تصاویر برای آموزش سیستمهای خودران.
- چالش: بسیار پرهزینه و زمانبر است.
ب) دادههای بدون برچسب (Unlabeled Data)
مخصوص یادگیری نظارتنشده (Unsupervised Learning).
- فقط داده خام وجود دارد و مدل باید خودش ساختار را پیدا کند.
- مثال: هزاران تراکنش بانکی که مدل باید الگوهای عجیب (کلاهبرداری) را در آنها پیدا کند.
- مزیت: ارزان و فراوان است.
6. چالشهای بزرگ در دادههای آموزشی
سوگیری (Bias)
این خطرناکترین مشکل است. اگر دادههای آموزشی سوگیری داشته باشند، هوش مصنوعی هم همان تعصبات را یاد میگیرد.
- مثال: اگر سیستم تشخیص چهره فقط با عکسهای مردان سفیدپوست آموزش دیده باشد، در تشخیص چهره زنان یا افراد رنگینپوست دچار خطای فاحش میشود.
بیشبرازش (Overfitting)
زمانی رخ میدهد که مدل دادههای آموزشی را “حفظ” میکند به جای اینکه “یاد بگیرد”.
- مثل دانشآموزی که عین جملات کتاب را حفظ کرده اما اگر سوال مفهومی بپرسید، نمیتواند جواب دهد. مدل در دادههای آموزشی عالی عمل میکند اما در دادههای جدید (تست) شکست میخورد.
حریم خصوصی (Data Privacy)
استفاده از دادههای واقعی کاربران (مثل سوابق پزشکی یا چتهای خصوصی) برای آموزش مدلها چالشهای قانونی و اخلاقی سنگینی دارد. (راه حلهایی مثل دادههای مصنوعی یا Synthetic Data برای حل این مشکل در حال ظهور هستند).
7. نتیجهگیری
در دنیای مدرن هوش مصنوعی، رقابت اصلی دیگر بر سر “الگوریتم بهتر” نیست (چون اکثر الگوریتمها متنباز هستند)؛ رقابت بر سر “داده بهتر” است. شرکتهایی مثل گوگل و تسلا به این دلیل پیشرو هستند که دسترسی انحصاری به کوهی از دادههای آموزشی باکیفیت و متنوع دارند. ساختن یک مدل هوش مصنوعی ۸۰٪ مهندسی داده و فقط ۲۰٪ مدلسازی است.