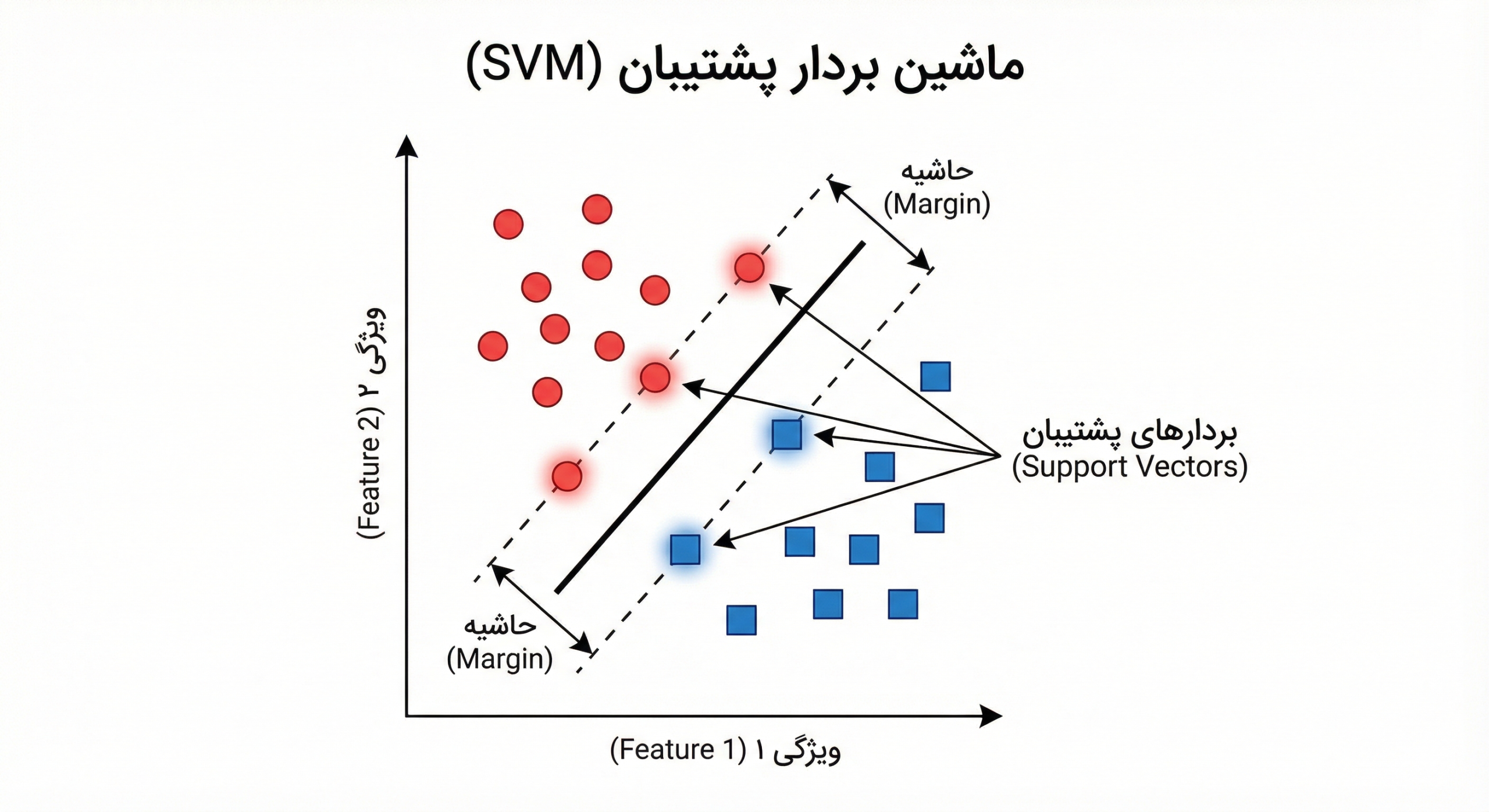
استخراج ویژگی (Feature Extraction): ترجمه زبان دنیا به زبان ماشین
نویسنده: فاطمه جعفری نوبخت
1. مقدمه
وقتی شما به یک “سیب” نگاه میکنید، مغزتان بلافاصله آن را پردازش نمیکند که “این مجموعهای از ۱۰ میلیون فوتون نوری است”. مغز شما ویژگیهای کلیدی را میبیند: “گرد است”، “قرمز است”، “ساقه دارد”.
در یادگیری ماشین، کامپیوترها دادهها را به صورت خام (اعداد و پیکسلها) میبینند. استخراج ویژگی (Feature Extraction) فرآیندی است که در آن، دادههای خام و حجیم را به مجموعهای از ویژگیهای عددیِ فشرده و معنیدار تبدیل میکنیم که برای ماشین قابلفهم و یادگیری باشد.
به عبارت ساده: اگر دادهها “نفت خام” باشند، استخراج ویژگی “پالایشگاهی” است که آن را به “بنزین” قابل مصرف برای موتور هوش مصنوعی تبدیل میکند.
2. تفاوت استخراج ویژگی و انتخاب ویژگی
این دو اصطلاح اغلب اشتباه گرفته میشوند، اما متفاوتند:
- انتخاب ویژگی (Feature Selection): از بین ۱۰۰ ستون داده، ۱۰ ستون مهمتر را انتخاب میکنیم و بقیه را دور میریزیم (حذف).
- استخراج ویژگی (Feature Extraction): ۱۰۰ ستون داده را با فرمولهای ریاضی ترکیب میکنیم تا ۱۰ ویژگی جدید بسازیم که اطلاعات آن ۱۰۰ ستون را در خود فشرده کردهاند (تغییر شکل).
3. چرا به استخراج ویژگی نیاز داریم؟
چرا مستقیماً دادههای خام را به مدل ندهیم؟
- نفرین ابعاد (Curse of Dimensionality): وقتی تعداد ورودیها (مثلاً پیکسلهای یک عکس ۴K) خیلی زیاد باشد، مدل برای یادگیری به حجم غیرممکنی از داده نیاز پیدا میکند.
- حذف نویز: دادههای خام پر از اطلاعات نامربوط هستند (مثلاً پسزمینه آسمان در عکس تشخیص ماشین). استخراج ویژگی روی “سیگنال اصلی” تمرکز میکند.
- افزایش سرعت: آموزش مدل با ۱۰ ویژگی، صدها بار سریعتر از آموزش با ۱۰,۰۰۰ ورودی خام است.
4. روشهای استخراج ویژگی (بر اساس نوع داده)
الف) برای دادههای جدولی (Numerical Data)
- PCA (تحلیل مولفههای اصلی): مشهورترین روش. این تکنیک با عملیات ریاضی، ابعاد دادهها را کاهش میدهد. مثلاً اگر “متراژ خانه” و “تعداد اتاق” همبستگی بالایی دارند، PCA آنها را در یک ویژگی جدید به نام “سایز کلی” ترکیب میکند.
ب) برای تصاویر (Computer Vision)
قبل از یادگیری عمیق، مهندسان به صورت دستی ویژگیها را طراحی میکردند:
- هیستوگرام رنگ: شمارش تعداد پیکسلهای قرمز، سبز و آبی.
- تشخیص لبه (Edge Detection): استفاده از فیلترهایی (مثل Sobel) برای پیدا کردن مرز اشیاء.
- SIFT و HOG: الگوریتمهایی که گوشهها و بافتهای خاص تصویر را پیدا میکنند (مثلاً تشخیص چرخهای ماشین).
ج) برای متن (NLP)
کامپیوتر کلمات را نمیفهمد، پس باید آنها را به عدد تبدیل کرد:
- Bag of Words (BoW): شمارش تعداد تکرار هر کلمه در متن.
- Word Embeddings (Word2Vec): تبدیل کلمات به بردارهای ریاضی، به طوری که کلمات با معنی نزدیک (مثل “شاه” و “ملکه”) در فضای ریاضی هم به هم نزدیک باشند.
5. انقلاب یادگیری عمیق: استخراج ویژگی خودکار
تا قبل از سال ۲۰۱۲، متخصصان سالها وقت صرف میکردند تا بفهمند “چگونه ویژگیهای یک گربه را برای کامپیوتر تعریف کنند” (مثلاً فاصله بین دو گوش).
اما شبکههای عصبی کانولوشنی (CNN) بازی را تغییر دادند.
در یادگیری عمیق، ما ویژگی تعریف نمیکنیم؛ خود شبکه ویژگیها را استخراج میکند.
- لایههای اولیه: خطوط و لبههای ساده را یاد میگیرند.
- لایههای میانی: اشکال هندسی (دایره، مربع) را میسازند.
- لایههای انتهایی: اجزای پیچیده (چشم، لاستیک، برگ درخت) را تشخیص میدهند.
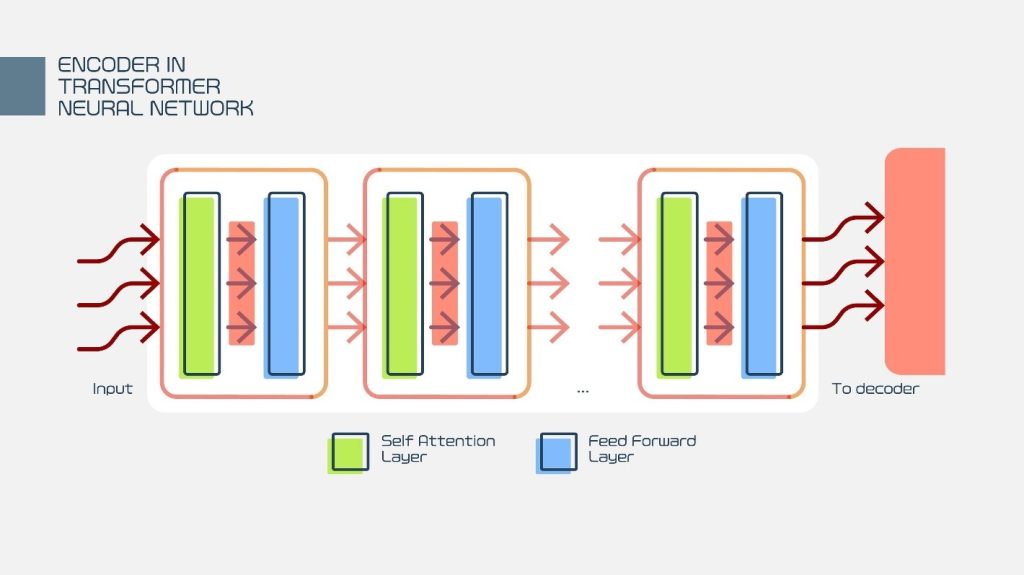
در واقع، بخشِ “Encoder” در یک شبکه عصبی، همان ماشینِ استخراج ویژگی است.
6. مثال کاربردی در GIS و محیط زیست
فرض کنید میخواهید سلامت جنگل را از روی تصاویر ماهوارهای بسنجید.
- داده خام: مقادیر بازتاب نور در باندهای قرمز (Red) و مادون قرمز نزدیک (NIR).
- استخراج ویژگی: شما فرمولی اعمال میکنید:
NDVI = \frac{(NIR – Red)}{(NIR + Red)}
در اینجا، NDVI یک ویژگی استخراج شده است. شما دو باند خام را ترکیب کردید تا یک ویژگی جدید بسازید که مستقیماً با “سلامت گیاه” در ارتباط است و برای مدل بسیار فهمیدنیتر از اعداد خام اولیه است.
7. نتیجهگیری
استخراج ویژگی کلید موفقیت مدل است. یک مدل ساده با ویژگیهای عالی، معمولاً بهتر از یک مدل پیچیده با ویژگیهای ضعیف عمل میکند. در دنیای مدرن هوش مصنوعی، گرایش به سمت استفاده از شبکههای عصبی است که این کار را به صورت خودکار انجام میدهند، اما درک منطق پشت آن برای تفسیر نتایج و بهبود مدلها ضروری است.