


ماشین بردار پشتیبان (SVM): مرزبان دقیق دنیای دادهها
نویسنده: فاطمه جعفری نوبخت
در بین الگوریتمهای یادگیری ماشین، Support Vector Machine یا به اختصار SVM، جایگاه ویژهای دارد. این الگوریتم که در دهه ۱۹۹۰ توسط ولادیمیر وپنیک (Vladimir Vapnik) توسعه یافت، به دلیل دقت ریاضی بالا و عملکرد فوقالعاده در مجموعههای داده کوچک تا متوسط، همچنان یکی از محبوبترین روشها برای طبقهبندی (Classification) و رگرسیون است.
در دنیای GIS و سنجش از دور، قبل از ظهور یادگیری عمیق (Deep Learning)، الگوریتم SVM پادشاه بیرقیب طبقهبندی تصاویر ماهوارهای بود.
1- مفهوم اصلی: پیدا کردن “بهترین” خط
فرض کنید تعدادی توپ قرمز و آبی روی یک میز دارید و میخواهید با یک چوب صاف، آنها را از هم جدا کنید. شما میتوانید چوب را در زوایای مختلفی قرار دهید تا توپها جدا شوند. اما کدام حالت بهترین است؟
SVM میگوید:
«بهترین خط، خطی است که بیشترین فاصله ممکن را از نزدیکترین توپهای قرمز و آبی داشته باشد.»
در این تعریف، سه مفهوم کلیدی وجود دارد:
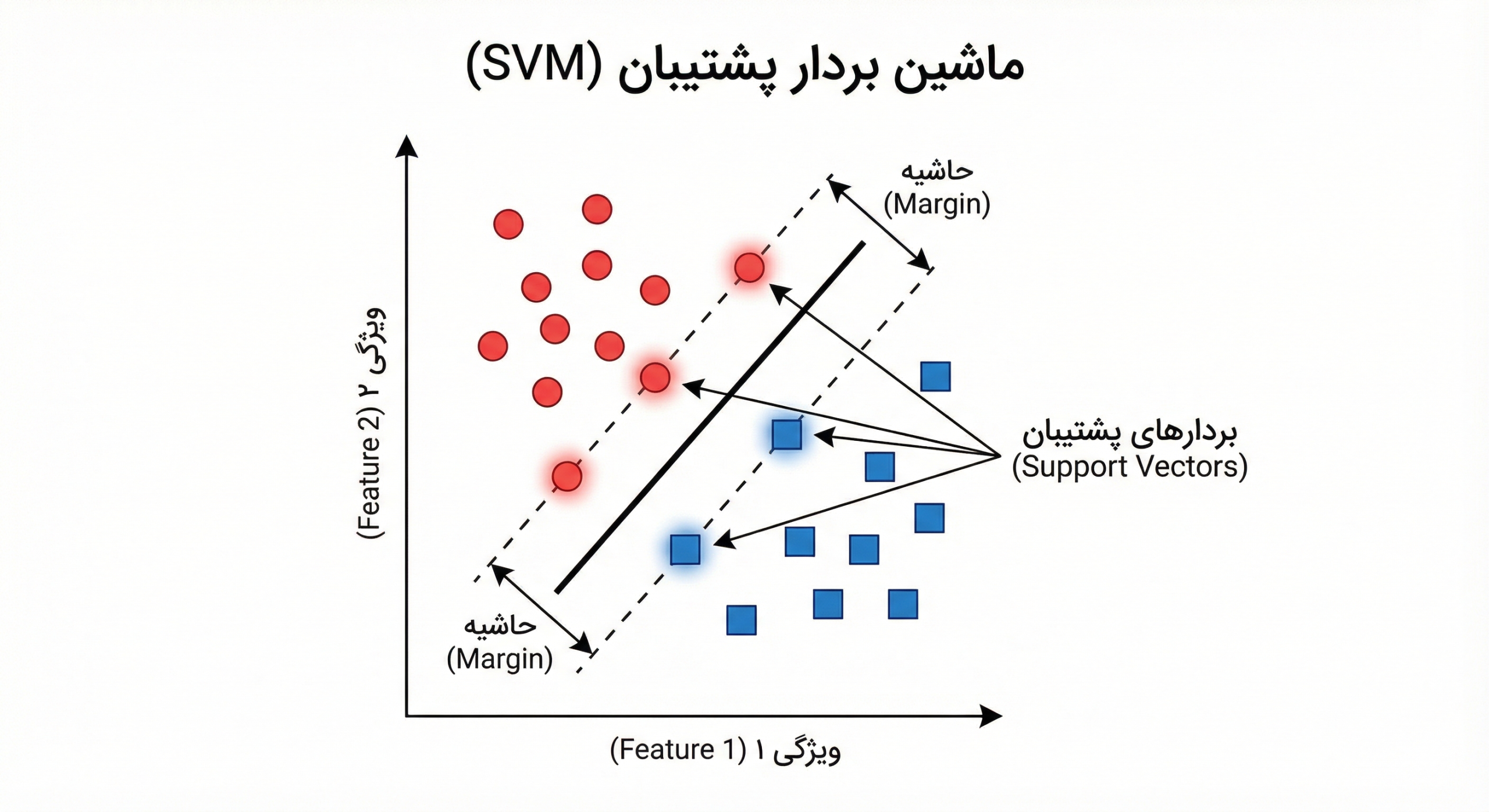
- ابرصفحه (Hyperplane): همان خط یا صفحهای که دادهها را جدا میکند. در دو بعد، یک خط است؛ در سه بعد، یک صفحه تخت؛ و در ابعاد بالاتر، “ابرصفحه” نامیده میشود.
- حاشیه (Margin): فاصله بین ابرصفحه تا نزدیکترین دادههای هر کلاس. SVM همیشه سعی میکند این حاشیه را ماکزیمم کند. هرچه حاشیه پهنتر باشد، مدل مطمئنتر است (مانند خیابانی که خطکشی وسط آن پهن است و احتمال تصادف را کم میکند).
- بردارهای پشتیبان (Support Vectors): نکته کلیدی اینجاست. SVM به تمام دادهها اهمیت نمیدهد؛ بلکه فقط به دادههای لبِ مرز نگاه میکند. این نقاط که نزدیکترین دادهها به خط جداکننده هستند، “بردارهای پشتیبان” نام دارند. اگر بقیه دادهها را حذف کنید و فقط این چند نقطه را نگه دارید، نتیجه تغییر نمیکند. کل مدل روی دوش این چند نقطه سوار است.
2- چالش دادههای غیرخطی و “حیله هسته” (Kernel Trick)
در دنیای واقعی، دادهها همیشه به راحتی با یک خط صاف جدا نمیشوند. مثلاً اگر دادههای قرمز وسط باشند و دادههای آبی دورتادور آنها حلقه زده باشند، هیچ خط صافی نمیتواند آنها را جدا کند.
اینجاست که جادوی SVM نمایان میشود: Kernel Trick.
تصور کنید دادههای قرمز و آبی روی یک کاغذ (دو بعدی) هستند و قابل تفکیک نیستند. SVM با استفاده از یک تابع ریاضی (کرنل)، دادهها را به بُعد بالاتر (سه بعدی) میبرد. انگار که با دست، وسط کاغذ (جایی که قرمزها هستند) را بالا میآورید. حالا قرمزها در ارتفاع بالاتری نسبت به آبیها قرار دارند و میتوانید یک صفحه تخت را از زیر قرمزها و بالای آبیها عبور دهید تا آنها را جدا کنید.
وقتی دوباره به حالت دو بعدی برگردید، آن صفحه تخت به شکل یک منحنی پیچیده و دقیق دیده میشود که دور دادههای قرمز خط کشیده است.
3- انواع کرنلهای معروف:
- خطی (Linear): برای دادههای ساده و تفکیکپذیر.
- چندجملهای (Polynomial): برای دادههای منحنی شکل.
- RBF (Radial Basis Function): محبوبترین کرنل در توانایی بالایی در جدا کردن پیچیدهترین کلاسها دارد.
4- مزایا و معایب ماشین بردار پشتیبان(SVM)
مزایا:
- دقت بالا در ابعاد زیاد: SVM در جاهایی که تعداد ویژگیها (Features) زیاد است (مثلاً تصاویر ابرطیفی یا Hyperspectral که صدها باند دارند) بسیار عالی عمل میکند.
- حافظه بهینه: چون مدل نهایی فقط با استفاده از چند نقطه (Support Vectors) تعریف میشود، حجم مدل کم است.
- عدم گیرافتادن در بهینه محلی (Global Optimum): برخلاف شبکههای عصبی که ممکن است در یک جواب “خوب” (و نه عالی) گیر کنند، SVM به دلیل ماهیت محدب (Convex) مسائل ریاضیاش، معمولاً بهترین جواب ممکن را پیدا میکند.
معایب:
- کند در دادههای بزرگ: اگر تعداد رکوردهای داده (مثلاً پیکسلها) خیلی زیاد باشد (مثلاً چند میلیون)، آموزش SVM بسیار زمانبر میشود.
- حساس به نویز: اگر دادههای پرت (Outliers) زیادی داشته باشید که در هم آمیخته باشند، پیدا کردن حاشیه مناسب برای SVM سخت میشود.
- عدم ارائه احتمالات: SVM مستقیماً میگوید “این کلاس A است”، و مثل برخی روشهای دیگر (مثل Logistic Regression) ذاتاً احتمال (مثلاً ۸۰٪ کلاس A) را ارائه نمیدهد (هرچند با روشهایی میتوان آن را محاسبه کرد).
5- کاربرد SVM در GIS و تحلیل محیط زیست
با وجود پیشرفت یادگیری عمیق، SVM هنوز در بسیاری از پروژههای سنجش از دور، انتخاب اول است، به خصوص وقتی دادههای آموزشی (Training Data) کمی دارید.
- طبقهبندی پوشش اراضی (LULC): برای تفکیک کلاسهای طیفی مشابه (مثلاً تفکیک انواع مختلف محصولات کشاورزی یا تفکیک آسفالت از بتن)، SVM اغلب بهتر از روشهای کلاسیک مثل Maximum Likelihood عمل میکند.
- تشخیص تغییرات (Change Detection): استفاده از SVM برای دستهبندی تغییرات شهری یا جنگلی در دو بازه زمانی.
- تحلیل تصاویر لیدار (LiDAR): برای طبقهبندی ابر نقاط (Point Clouds) به زمین، ساختمان و گیاه.
6- نتیجهگیری
ماشین بردار پشتیبان (SVM) یک الگوریتم قدرتمند، ریاضیمحور و قابل اعتماد است. اگرچه شاید “هیجان” شبکههای عصبی عمیق (Deep Learning) را نداشته باشد، اما در پروژههایی که دادههای آموزشی محدود هستند و نیاز به دقت بالایی دارید (شرایطی که در پروژههای محیط زیستی ایران بسیار رایج است)، SVM یک ابزار نجاتبخش و ضروری در جعبهابزار یک مشاور GIS است.
درباره نویسنده:
فاطمه جعفری نوبخت، متخصص برجسته و پژوهشگر حوزه مهندسی محیط زیست، با رویکردی نوین دانش کلاسیک این رشته را با فناوریهای پیشرفته هوش مصنوعی تلفیق کرده و به عنوان پیشگام در زمینه هوش مصنوعی مکانی (GeoAI) شناخته میشود. وی با تکیه بر مدرک کارشناسی ارشد مهندسی محیط زیست و درک عمیق از اکوسیستمها، تخصص خود را فراتر از روشهای سنتی گسترش داده و با ورود به دنیای دادهها، فعالیتهای حرفهای خود را بر کاربرد هوش مصنوعی در علوم محیط زیست متمرکز کرده است. او هماکنون به عنوان مشاور ارشد علوم مکانی در محیط زیست و منابع طبیعی، با استفاده از الگوریتمهای پیشرفته در پی راهکارهایی برای پایش دقیق، پیشبینی تغییرات اقلیمی و مدیریت بهینه منابع است. فاطمه جعفری با باور بنیادین به اینکه «مهمترین توجه انسانها باید به مقوله محیط زیست باشد»، تکنولوژی را ابزاری قدرتمند برای نجات زمین میداند و علاوه بر پروژههای استراتژیک، با برگزاری مستمر کارگاههای آموزشی در زمینه علوم مکانی و زمین، مشتاقانه به انتقال دانش و تربیت نسلی متخصص برای حفاظت از آینده محیط زیست میپردازد.







