


خوشهبندی K-Means: هنرِ یافتن نظم در آشوب
نویسنده: فاطمه جعفری نوبخت
فرض کنید یک جعبه بزرگ پر از سنگهای معدنی مختلف دارید که هیچ برچسبی ندارند. شما نمیدانید نام هر سنگ چیست، اما میخواهید آنها را دستهبندی کنید. راه حل شما احتمالاً این است: سنگهای قرمز را یک طرف، سنگهای براق را یک طرف و سنگهای سنگین را طرف دیگر میگذارید.
این دقیقاً کاری است که K-Means Clustering با دادهها انجام میدهد. این الگوریتم، دادههای خام و بدون برچسب را میگیرد و بر اساس شباهت ذاتی آنها، گروهبندی (Cluster) میکند.
1- تعریف فنی
الگوریتم K-Means یک روش یادگیری بدون نظارت(Unsupervised Learning) است که دادهها را به K گروه مجزا تقسیم میکند؛ بهطوریکه دادههای داخل یک گروه بیشترین شباهت را به هم داشته باشند و دادههای گروههای مختلف بیشترین تفاوت را.
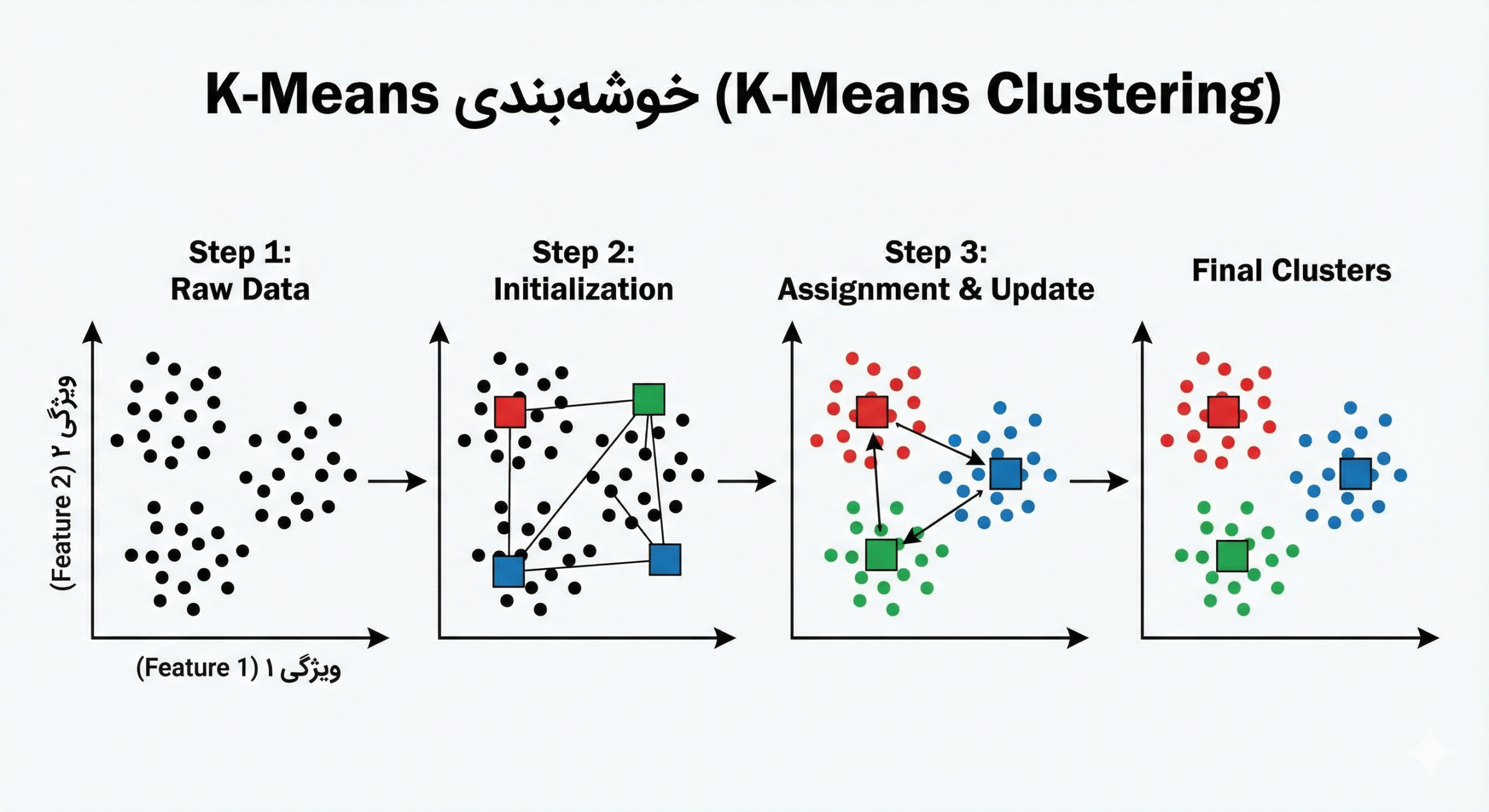
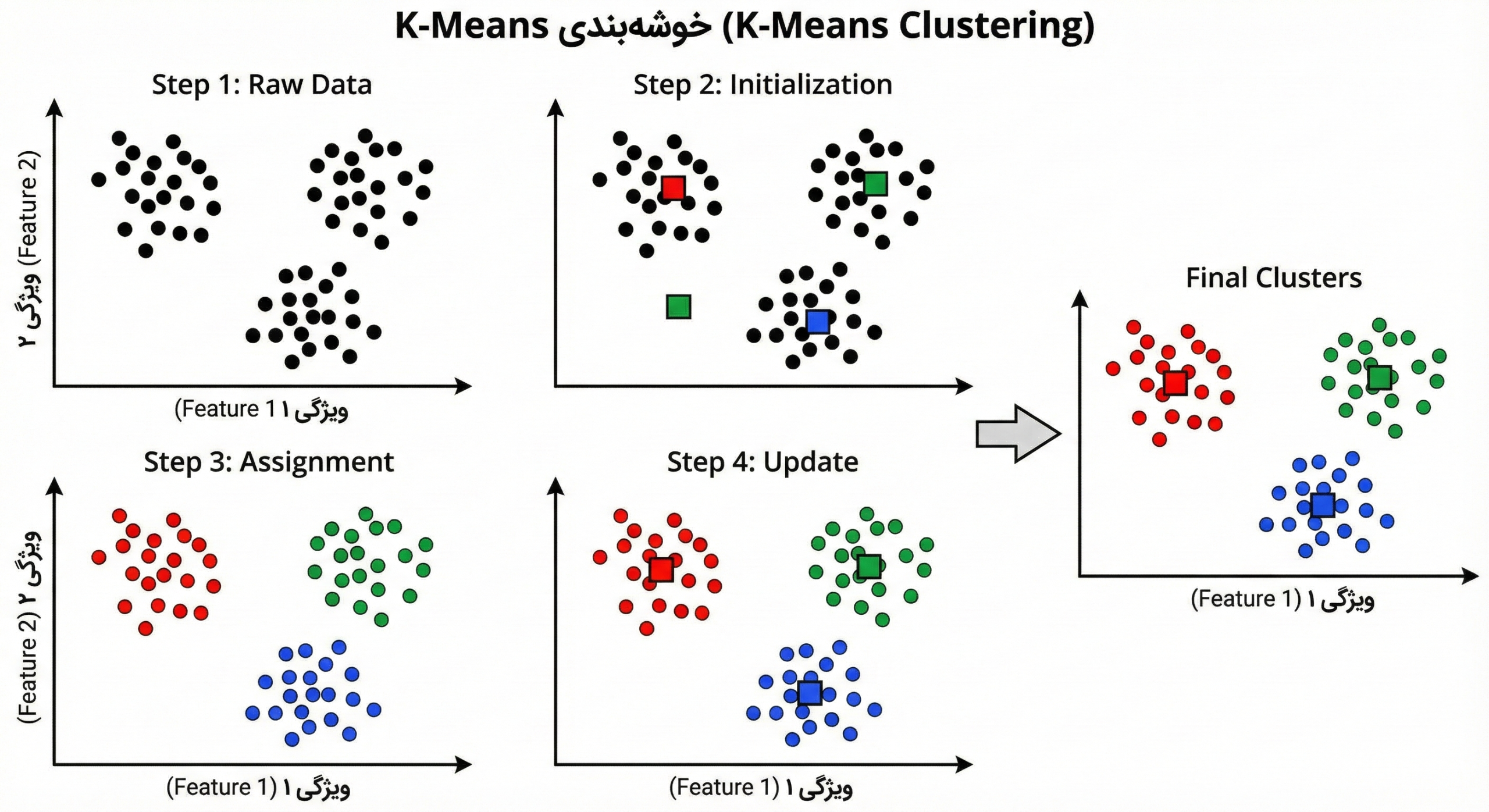
2- الگوریتم چگونه کار میکند؟ (رقص نقاط و مراکز)
کارکرد K-Means بسیار ساده اما قدرتمند است. این الگوریتم سعی دارد نقاط مرکزی (Centroids) را پیدا کند که نماینده هر گروه باشند. مراحل کار به شرح زیر است:
- انتخاب تعداد خوشهها (K): ابتدا باید به الگوریتم بگویید چند گروه میخواهید (مثلاً K=3).
- مقداردهی اولیه (Initialization): الگوریتم به صورت تصادفی ۳ نقطه را در فضا به عنوان “مرکز اولیه” انتخاب میکند.
- تخصیص (Assignment): فاصله تکتک دادهها تا این ۳ مرکز محاسبه میشود. هر داده به نزدیکترین مرکز ملحق میشود. اکنون ۳ گروه موقت تشکیل شده است.
- بهروزرسانی (Update): حال که گروهها مشخص شدند، مرکز هندسی (میانگین) نقاط هر گروه محاسبه میشود و مرکز خوشه به این نقطه جدید منتقل میشود.
- تکرار (Iteration): مراحل ۳ و ۴ آنقدر تکرار میشوند تا مراکز دیگر جابجا نشوند (همگرایی رخ دهد).
3- چالش اصلی: بهترین K کدام است؟ (روش آرنج)
بزرگترین سوال در K-Means این است: «از کجا بدانیم دادههای ما باید به ۳ گروه تقسیم شوند یا ۵ گروه؟»
برای حل این مشکل از روشی به نام روش آرنج (Elbow Method) استفاده میشود.
در این روش، الگوریتم را برای Kهای مختلف (مثلاً از ۱ تا ۱۰) اجرا میکنیم و خطای مدل (مجموع مربعات فاصله نقاط از مرکز خوشه یا WCSS) را محاسبه میکنیم.
- وقتی تعداد خوشهها کم است، خطا زیاد است.
- با افزایش خوشهها، خطا کم میشود.
- نمودار خطا شبیه به یک “دست” است. نقطهای که نمودار در آن ناگهان میشکند و صاف میشود (آرنج دست)، بهترین تعداد خوشه است.
4- مزایا و معایب
مزایا:
- سادگی و سرعت: درک آن آسان است و برای دادههای بزرگ بسیار سریعتر از روشهای دیگر عمل میکند.
- انطباقپذیری: اگر داده جدیدی اضافه شود، به راحتی میتوان مرکز خوشهها را آپدیت کرد.
معایب:
- نیاز به تعیین K: برخلاف برخی الگوریتمها، باید از اول تعداد گروهها را حدس بزنید.
- حساس به نویز (Outliers): یک داده پرت که خیلی دورتر از بقیه باشد، میتواند میانگین (Centroid) را به شدت جابجا کند و کل گروهبندی را خراب کند.
- فقط خوشههای کروی: K-Means فرض میکند که خوشهها گرد و هماندازه هستند. اگر دادههای شما به شکل هلال ماه یا درهمتنیده باشند، K-Means عملکرد ضعیفی دارد.
5- کاربرد در GIS و تحلیل فضایی
برای متخصصان GIS، الگوریتم K-Means ابزاری حیاتی برای تحلیلهای اکتشافی است:
- طبقهبندی تصاویر ماهوارهای (Unsupervised Classification): وقتی هیچ داده زمینی (Ground Truth) ندارید، K-Means پیکسلهای تصویر را صرفاً بر اساس اعداد طیفی (رنگ) دستهبندی میکند. مثلاً تمام پیکسلهای سبز تیره را در یک گروه میگذارد (که احتمالاً جنگل هستند) و پیکسلهای آبی را در گروه دیگر.
- مکانیابی بهینه خدمات (Location-Allocation): فرض کنید میخواهید ۵ ایستگاه آتشنشانی در شهر بسازید. نقاط وقوع حریق در سال گذشته را به عنوان داده ورودی به K-Means میدهید و K=5 را تنظیم میکنید. مراکز نهایی خوشهها، بهترین مکانها برای احداث ایستگاه هستند تا میانگین فاصله رسیدن به حریقها حداقل شود.
- تحلیل جرم (Crime Analysis):شناسایی کانونهای جرمخیز (Hot Spots) با گروهبندی مکانهای وقوع جرم.
6- تفاوت با SVM و درخت تصمیم
- SVM و درخت تصمیم (با ناظر): شما به مدل میگویید: «این نمونهها “شهر” هستند و اینها “آب”». مدل یاد میگیرد تا دادههای جدید را تشخیص دهد.
- K-Means (بدون ناظر): شما به مدل هیچ چیزی نمیگویید. مدل خودش میگوید: «من در این دادهها ۳ نوع الگوی متفاوت پیدا کردم، حالا خودت بررسی کن ببین اینها چه هستند.»
7- نتیجهگیری
الگوریتم K-Means دروازه ورود به دنیای دادهکاوی بدون برچسب است. اگرچه ساده است، اما در بسیاری از مسائل پیچیده مکانی، اولین و گاهی بهترین راه برای شناخت ساختار پنهان دادههاست. این روش به خصوص در مراحل اولیه پروژههای سنجش از دور که هنوز بازدید میدانی انجام نشده، بسیار کارآمد است.
درباره نویسنده:
فاطمه جعفری نوبخت، متخصص برجسته و پژوهشگر حوزه مهندسی محیط زیست، با رویکردی نوین دانش کلاسیک این رشته را با فناوریهای پیشرفته هوش مصنوعی تلفیق کرده و به عنوان پیشگام در زمینه هوش مصنوعی مکانی (GeoAI) شناخته میشود. وی با تکیه بر مدرک کارشناسی ارشد مهندسی محیط زیست و درک عمیق از اکوسیستمها، تخصص خود را فراتر از روشهای سنتی گسترش داده و با ورود به دنیای دادهها، فعالیتهای حرفهای خود را بر کاربرد هوش مصنوعی در علوم محیط زیست متمرکز کرده است. او هماکنون به عنوان مشاور ارشد علوم مکانی در محیط زیست و منابع طبیعی، با استفاده از الگوریتمهای پیشرفته در پی راهکارهایی برای پایش دقیق، پیشبینی تغییرات اقلیمی و مدیریت بهینه منابع است. فاطمه جعفری با باور بنیادین به اینکه «مهمترین توجه انسانها باید به مقوله محیط زیست باشد»، تکنولوژی را ابزاری قدرتمند برای نجات زمین میداند و علاوه بر پروژههای استراتژیک، با برگزاری مستمر کارگاههای آموزشی در زمینه علوم مکانی و زمین، مشتاقانه به انتقال دانش و تربیت نسلی متخصص برای حفاظت از آینده محیط زیست میپردازد.






