یادگیری تقویتی (Reinforcement Learning): آموزش از طریق آزمون و خطا
نویسنده: فاطمه جعفری نوبخت
اگر هوش مصنوعی را به یک کودک تشبیه کنیم، “یادگیری نظارت شده” مانند یادگیری در کلاس درس با معلم است، اما یادگیری تقویتی (RL) مانند یادگیری دوچرخهسواری در حیاط خانه است. هیچکس دقیقاً به شما نمیگوید چقدر فرمان را بپیچانید؛ شما رکاب میزنید، زمین میخورید (تنبيه)، تعادل خود را حفظ میکنید (پاداش)، و به مرور زمان یاد میگیرید که چگونه دوچرخه را برانید.
یادگیری تقویتی نزدیکترین شاخه از هوش مصنوعی به نحوه یادگیری انسانها و حیوانات است و هدف آن تربیت عاملهایی است که بتوانند در محیطهای پیچیده تصمیمگیری کنند.
۱. جایگاه RL در دنیای یادگیری ماشین
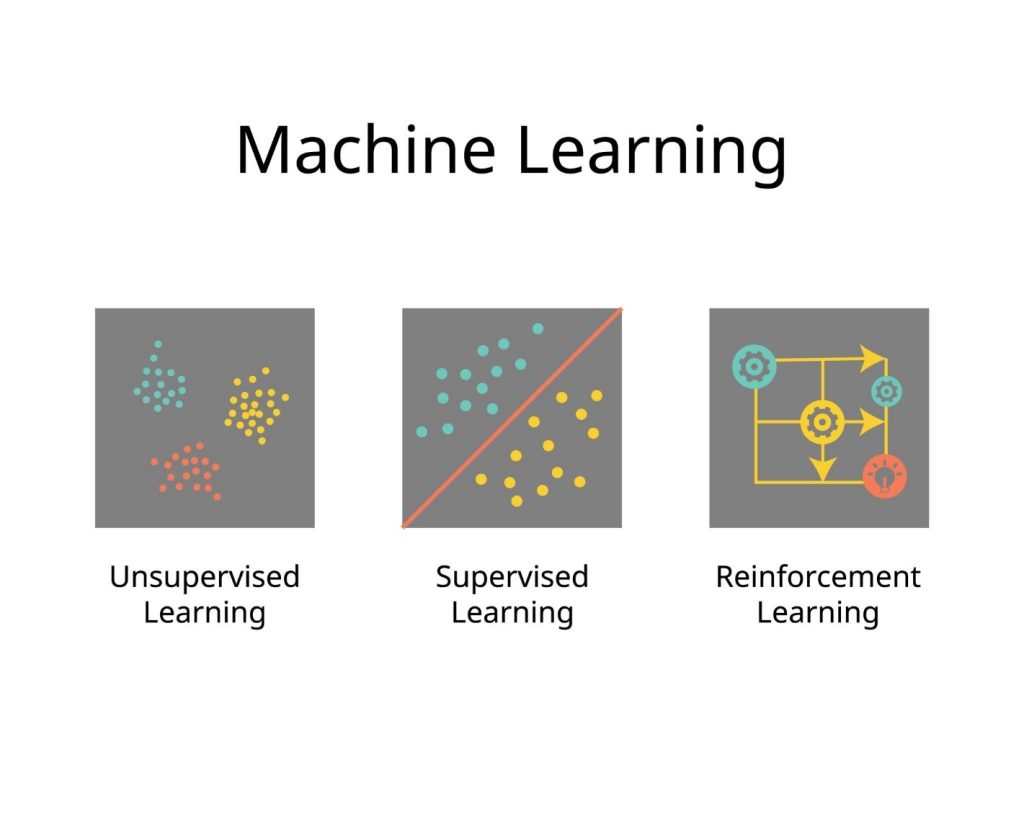
برای درک بهتر، بیایید جایگاه RL را در کنار دو روش اصلی دیگر مقایسه کنیم:
- یادگیری نظارت شده (Supervised Learning): دادهها برچسب دارند (مثل تشخیص عکس گربه). مدل میداند پاسخ صحیح چیست.
- یادگیری نظارت نشده (Unsupervised Learning): دادهها برچسب ندارند (مثل خوشهبندی مشتریان). مدل الگوهای پنهان را پیدا میکند.
- یادگیری تقویتی (Reinforcement Learning): دادهای از قبل وجود ندارد. عامل با محیط تعامل میکند و بازخورد (Feedback) میگیرد.
۲. چرخه اصلی: عامل، محیط و پاداش
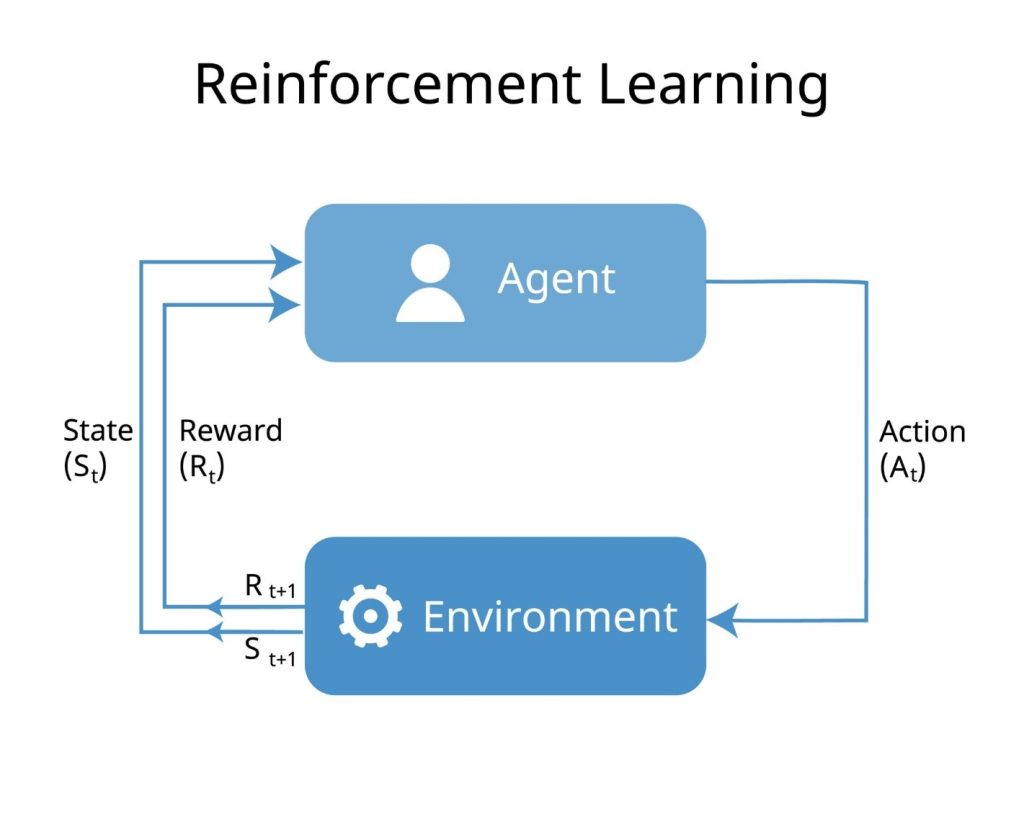
قلب تپنده یادگیری تقویتی، یک چرخه تعاملی است. بیایید اجزای این چرخه را با زبان فنی تعریف کنیم:
- عامل (Agent): موجود هوشمندی که یاد میگیرد (مثلاً روبات یا شخصیت بازی).
- محیط (Environment): دنیایی که عامل در آن فعالیت میکند (مثلاً صفحه شطرنج یا یک شهر شبیهسازی شده).
- حالت (State – S): وضعیت فعلی عامل در محیط.
- کنش (Action – A): تصمیمی که عامل میگیرد و انجام میدهد.
- پاداش (Reward – R): بازخوردی که محیط پس از انجام کنش به عامل میدهد (میتواند مثبت یا منفی باشد).
فرآیند:
- عامل در حالت $S_t$ قرار دارد.
- کنش $A_t$ را انتخاب میکند.
- محیط تغییر میکند و به حالت جدید $S_{t+1}$ میرود.
- عامل پاداش $R_{t+1}$ را دریافت میکند.
- هدف عامل: بیشینه کردن مجموع پاداشها در طول زمان است.
۳. چالش بزرگ: اکتشاف در برابر استخراج (Exploration vs. Exploitation)
یکی از مهمترین مفاهیم فلسفی و ریاضی در RL، تضاد بین این دو مفهوم است:
- اکتشاف (Exploration): امتحان کردن راههای جدیدی که شاید پاداش بیشتری داشته باشند (ریسک کردن). مثل رفتن به رستورانی که تا حالا نرفتهاید.
- استخراج (Exploitation): استفاده از دانش فعلی برای گرفتن بیشترین پاداش مطمئن. مثل رفتن به رستوران محبوب همیشگی.
یک عامل هوشمند باید تعادلی بین این دو برقرار کند. اگر فقط استخراج کند، هرگز راههای بهتر را پیدا نمیکند. اگر فقط اکتشاف کند، هرگز از دانش خود بهره نمیبرد.
۴. مفاهیم ریاضی کلیدی
برای درک عمیقتر، باید با دو مفهوم ریاضی آشنا شویم:
سیاست (Policy – \pi)
سیاست، “مغز” عامل است. تابعی است که مشخص میکند در هر حالت، چه کنشی باید انجام شود. سیاست میتواند قطعی (Deterministic) یا احتمالی (Stochastic) باشد.
تابع ارزش (Value Function – V)
تفاوت “پاداش” و “ارزش” بسیار مهم است:
- پاداش: لذت لحظهای (خوردن شکلات).
- ارزش: خوبیِ بلندمدتِ بودن در یک حالت خاص (سالم بودن).
تابع ارزش تخمین میزند که اگر در حالت S باشیم، تا پایان بازی چه مقدار پاداش جمع خواهیم کرد.
۵. الگوریتمهای مشهور
دنیای RL بسیار وسیع است، اما چند الگوریتم نقش کلیدی دارند:
۱. Q-Learning (روش مبتنی بر ارزش)
یک روش کلاسیک که جدولی از تمام حالتها و کنشهای ممکن میسازد (Q-Table). عامل یاد میگیرد که هر کنش در هر حالت چقدر “کیفیت” (Quality) دارد.
- محدودیت: برای محیطهای پیچیده با حالتهای بینهایت (مثل دنیای واقعی) کارایی ندارد زیرا جدول بینهایت بزرگ میشود.
۲. Deep Q-Networks (DQN)
ترکیب یادگیری عمیق (Deep Learning) با Q-Learning. به جای یک جدول بزرگ، از یک شبکه عصبی برای تخمین بهترین حرکت استفاده میشود. این همان الگوریتمی است که شرکت DeepMind گوگل با آن توانست بازیهای آتاری را فراتر از انسان بازی کند.
۳. Policy Gradients (روش مبتنی بر سیاست)
در این روش (مانند الگوریتم PPO)، شبکه عصبی مستقیماً یاد میگیرد که چه کاری انجام دهد (سیاست را بهینه میکند)، بدون اینکه لزوماً ارزش هر حالت را دقیق محاسبه کند. این روش برای محیطهای پویا و پیوسته (مثل کنترل بازوی ربات) عالی است.
۶. کاربردهای شگفتانگیز
یادگیری تقویتی فراتر از بازیهای کامپیوتری رفته و در حال حل مشکلات واقعی است:
- رباتیک: آموزش راه رفتن، گرفتن اجسام و حفظ تعادل به رباتها بدون برنامهنویسی دستی حرکات.
- خودروهای خودران: تصمیمگیری در ترافیک، تغییر لاین و پارک کردن.
- مدیریت منابع انرژی: گوگل با استفاده از RL مصرف برق دیتاسنترهای خود را تا ۴۰٪ کاهش داد (عامل یاد گرفت سیستم خنککننده را بهینه کند).
- معاملات مالی (Trading): رباتهایی که یاد میگیرند چه زمانی سهام بخرند یا بفروشند تا سود را در بلندمدت ماکزیمم کنند.
۷. چالشها و محدودیتها
چرا هنوز همهچیز با RL انجام نمیشود؟
- نیاز به داده زیاد (Sample Inefficiency): یک انسان با دیدن یک تصادف رانندگی یاد میگیرد، اما یک عامل RL ممکن است نیاز داشته باشد هزاران بار در شبیهساز تصادف کند تا یاد بگیرد.
- طراحی پاداش (Reward Shaping): تعریف دقیق پاداش دشوار است. اگر به جاروبرقی هوشمند بگویید “خاک جمع کن”، ممکن است خاک را بریزد و دوباره جمع کند تا مدام پاداش بگیرد! (این پدیده Reward Hacking نام دارد).
8- نتیجهگیری
یادگیری تقویتی گامی بلند به سوی هوش مصنوعی عمومی (AGI) است. این تکنولوژی به ماشینها اجازه میدهد تا نه فقط بر اساس دادههای گذشته، بلکه از طریق تعامل خلاقانه با محیط، مسائل را حل کنند. اگرچه پیادهسازی آن دشوار است، اما پتانسیل آن برای بهینهسازی سیستمهای پیچیده بینظیر است.