



یادگیری ماشین (Machine Learning): وقتی کامپیوترها تجربه میاندوزند
تا چند دهه پیش، تنها راه برای اینکه کامپیوتر کاری را انجام دهد، نوشتن دستورالعملهای دقیق و قدمبهقدم برای آن بود (برنامهنویسی سنتی). اما اگر بخواهیم به کامپیوتر یاد بدهیم “گربه” را در عکس تشخیص دهد، چه؟ نوشتن قوانین برای تعریف شکل گوش یا سبیل گربه تقریباً غیرممکن است.
اینجاست که یادگیری ماشین (ML) متولد میشود.
به جای کدنویسیِ قوانین، ما به کامپیوتر داده میدهیم و اجازه میدهیم خودش قوانین را کشف کند.
۱. تعریف ساده یادگیری ماشین
آرتور ساموئل (از پیشگامان این حوزه) در سال ۱۹۵۹ تعریف زیبایی ارائه داد:
“یادگیری ماشین حوزهای از مطالعات است که به کامپیوترها توانایی یادگیری میدهد، بدون اینکه صریحاً برای آن کار برنامهنویسی شده باشند.”
در واقع، ML علمِ تبدیل “دادههای گذشته” به “پیشبینیهای آینده” است.
۲. سه سبک اصلی یادگیری (Types of Learning)
ماشینها به سه روش اصلی یاد میگیرند که شبیه روشهای یادگیری انسان است:
الف) یادگیری نظارتشده (Supervised Learning)
- شیوه: مثل یادگیری دانشآموز با معلم.
- نحوه کار: ما به مدل، دادههای ورودی را همراه با پاسخ صحیح (برچسب) میدهیم. مثلاً هزاران عکس به او نشان میدهیم و میگوییم “این گربه است” یا “این سگ است”. مدل با دیدن این مثالها، الگوها را یاد میگیرد.
- کاربردها: تشخیص ایمیلهای اسپم، پیشبینی قیمت مسکن، تشخیص بیماری از روی عکس رادیولوژی.
- الگوریتمهای معروف: رگرسیون خطی (Linear Regression)، درخت تصمیم (Decision Tree).
ب) یادگیری نظارت نشده (Unsupervised Learning)
- شیوه: یادگیری بدون معلم؛ کشف خودکار.
- نحوه کار: دادهها هیچ برچسبی ندارند. ما فقط دادههای خام را به سیستم میدهیم و میگوییم “خودت ساختار یا الگویی در اینها پیدا کن”. مدل سعی میکند دادههای شبیه به هم را دستهبندی کند.
- کاربردها: بخشبندی مشتریان (Customer Segmentation) در بازاریابی، کشف ناهنجاری در تراکنشهای بانکی.
- الگوریتم معروف: خوشهبندی K-Means.
ج) یادگیری تقویتی (Reinforcement Learning)
- شیوه: یادگیری با آزمون و خطا (مانند یادگیری دوچرخهسواری یا بازی شطرنج).
- نحوه کار: عامل هوشمند (Agent) در یک محیط قرار میگیرد. اگر کار خوبی انجام داد، “پاداش” میگیرد و اگر اشتباه کرد، “تنبیه” میشود. هدف او به حداکثر رساندن پاداش نهایی است.
- کاربردها: رباتیک، بازیهای کامپیوتری، خودروهای خودران.
۳. فرآیند اجرای یک پروژه ML
یک مدل یادگیری ماشین چگونه ساخته میشود؟ این پروسه ۵ مرحله کلیدی دارد:
- جمعآوری داده (Data Collection): سوخت ماشین، داده است. هرچه داده بیشتر و باکیفیتتر، نتیجه بهتر.
- پیشپردازش (Data Preprocessing): تمیز کردن دادهها (حذف دادههای پرت، پر کردن جاهای خالی). قانون معروف: Garbage In, Garbage Out (اگر آشغال وارد سیستم کنی، آشغال تحویل میگیری).
- انتخاب مدل (Model Selection): انتخاب الگوریتم مناسب بر اساس نوع مسئله.
- آموزش (Training): مرحلهای که مدل روی دادهها کار میکند تا الگوها را یاد بگیرد.
- تست و ارزیابی (Evaluation): مدل را با دادههایی که تا به حال ندیده امتحان میکنیم تا ببینیم چقدر دقیق است.
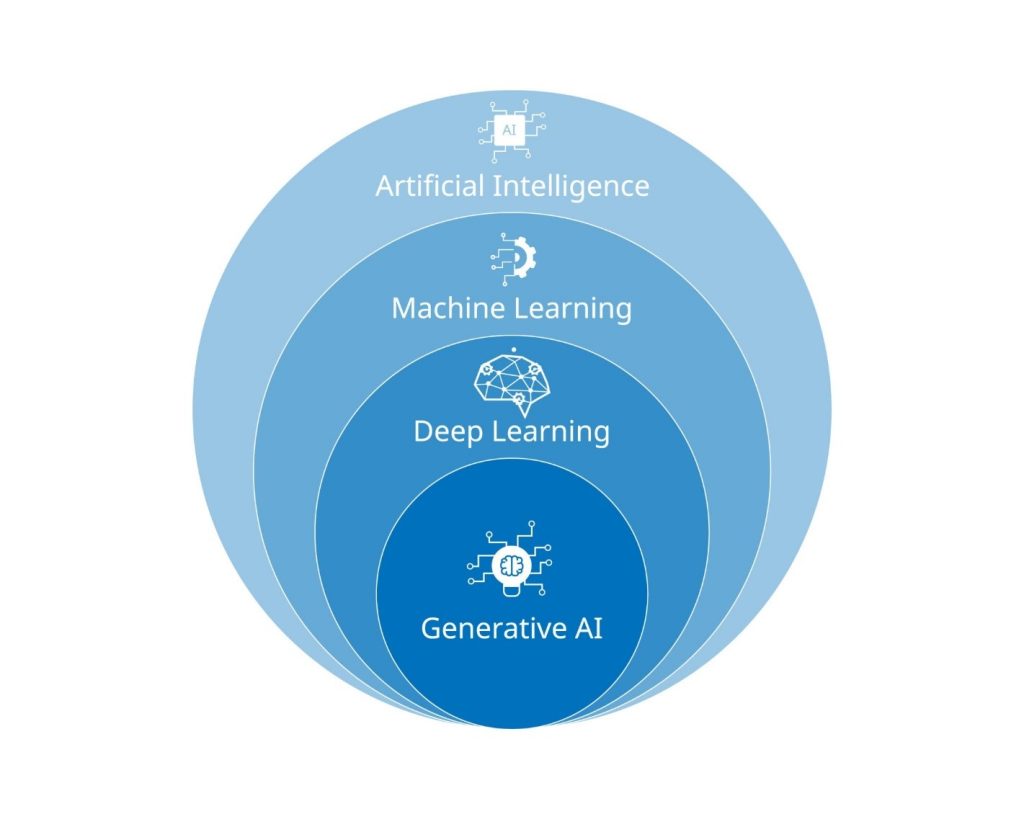
۴. تفاوت یادگیری ماشین و یادگیری عمیق (Deep Learning)
این یکی از رایجترین سوالات است.
- یادگیری ماشین (ML): دسته مادر است. شامل الگوریتمهای ساده و پیچیده میشود. معمولاً نیاز دارد که انسان ویژگیهای مهم (Features) را به آن معرفی کند.
- یادگیری عمیق (Deep Learning): زیرمجموعهای از ML است که از شبکههای عصبی مصنوعی (Artificial Neural Networks) با لایههای زیاد استفاده میکند. این روش شبیه مغز انسان عمل میکند و خودش ویژگیهای مهم را از داده استخراج میکند. برای پردازش تصویر و صدا عالی است اما به داده و قدرت پردازش بسیار زیادی نیاز دارد.
۵. چالشهای یادگیری ماشین
همه چیز گل و بلبل نیست؛ ML محدودیتهایی دارد:
- بیشبرازش (Overfitting): وقتی مدل دادههای آموزشی را حفظ میکند اما نمیتواند الگوهای کلی را یاد بگیرد (مثل دانشآموزی که شب امتحان کتاب را حفظ میکند اما مفهوم را نمیفهمد).
- سوگیری (Bias): اگر دادههای ورودی جهتگیری داشته باشند، مدل هم نژادپرست یا تبعیضآمیز عمل خواهد کرد.
- جعبه سیاه (Black Box): در مدلهای پیچیده (مثل دیپ لرنینگ)، گاهی نمیدانیم مدل چرا و چگونه به یک نتیجه خاص رسیده است.
۶. آینده: ماشینها تا کجا پیش میروند؟
یادگیری ماشین در حال تبدیل شدن به یک ابزار عمومی (Utility) مانند برق است. در آینده، ما کمتر درباره “خودِ یادگیری ماشین” صحبت خواهیم کرد و بیشتر شاهد کاربرد نامحسوس آن در همه چیز خواهیم بود؛ از یخچالی که لیست خرید مینویسد تا پزشکی که با دستیار هوشمندش سرطان را در مراحل اولیه درمان میکند.
7. جمعبندی
یادگیری ماشین جادو نیست؛ ریاضیات و آمار است که با سرعت بالا روی حجم زیادی از داده اجرا میشود. این فناوری ابزاری است که به ما کمک میکند الگوهای پنهان جهان را کشف کنیم و تصمیمات هوشمندانهتری بگیریم.
درباره نویسنده:
فاطمه جعفری نوبخت، متخصص برجسته و پژوهشگر حوزه مهندسی محیط زیست، با رویکردی نوین دانش کلاسیک این رشته را با فناوریهای پیشرفته هوش مصنوعی تلفیق کرده و به عنوان پیشگام در زمینه هوش مصنوعی مکانی (GeoAI) شناخته میشود. وی با تکیه بر مدرک کارشناسی ارشد مهندسی محیط زیست و درک عمیق از اکوسیستمها، تخصص خود را فراتر از روشهای سنتی گسترش داده و با ورود به دنیای دادهها، فعالیتهای حرفهای خود را بر کاربرد هوش مصنوعی در علوم محیط زیست متمرکز کرده است. او هماکنون به عنوان مشاور ارشد علوم مکانی در محیط زیست و منابع طبیعی، با استفاده از الگوریتمهای پیشرفته در پی راهکارهایی برای پایش دقیق، پیشبینی تغییرات اقلیمی و مدیریت بهینه منابع است. فاطمه جعفری با باور بنیادین به اینکه «مهمترین توجه انسانها باید به مقوله محیط زیست باشد»، تکنولوژی را ابزاری قدرتمند برای نجات زمین میداند و علاوه بر پروژههای استراتژیک، با برگزاری مستمر کارگاههای آموزشی در زمینه علوم مکانی و زمین، مشتاقانه به انتقال دانش و تربیت نسلی متخصص برای حفاظت از آینده محیط زیست میپردازد.





