


درخت تصمیم (Decision Tree): شفافیت در قلب هوش مصنوعی
نویسنده: فاطمه جعفری نوبخت
در دنیای الگوریتمهای پیچیده هوش مصنوعی که اغلب مانند یک “جعبه سیاه” (Black Box) عمل میکنند و کسی نمیداند دقیقاً در داخلشان چه میگذرد، درخت تصمیم یک استثنای درخشان است. این الگوریتم دقیقاً همانطور فکر میکند که یک انسان منطقی تصمیم میگیرد: با پرسیدن سوالات پیاپی و رسیدن به جواب نهایی.
1- درخت تصمیم چیست؟
درخت تصمیم یک مدل ساختاریافته فلوچارت-مانند است که برای طبقهبندی (Classification) و رگرسیون (Regression) استفاده میشود. این مدل، دادهها را بر اساس ویژگیهایشان (Features) دائماً به بخشهای کوچکتر تقسیم میکند تا زمانی که تمام اعضای یک گروه شبیه هم باشند.
مثال ساده: فرض کنید میخواهید تصمیم بگیرید “آیا امروز به کوهنوردی بروم؟”
- سوال اول: هوا بارانی است؟
- بله: نمیروم (پایان).
- خیر: (برو به سوال بعد).
- سوال دوم: باد شدید است؟
- بله: نمیروم (پایان).
- خیر: میروم (پایان).
این سلسله مراتب سوالات، یک درخت تصمیم را میسازد.
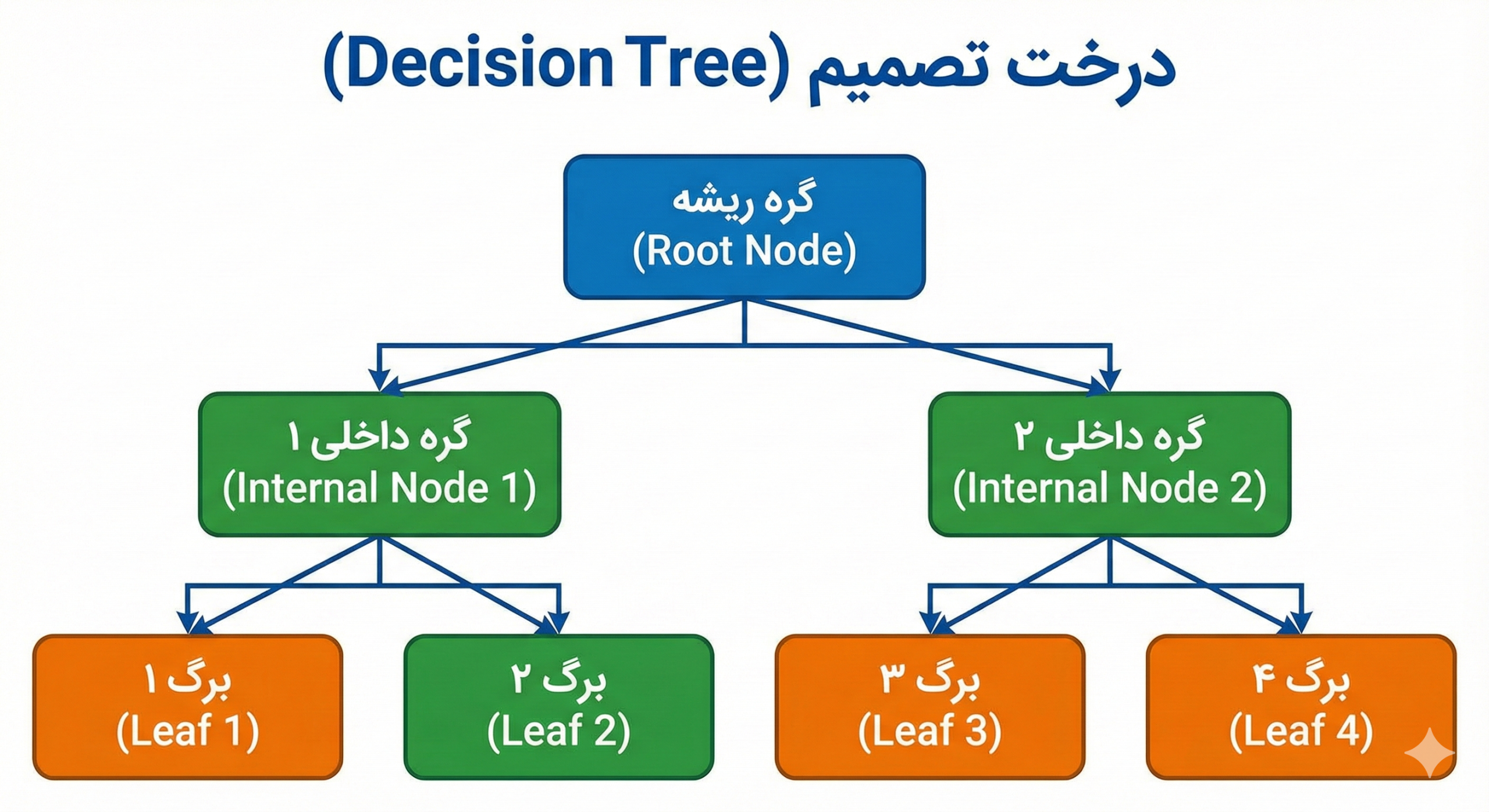
2- آناتومی یک درخت
برای درک این الگوریتم، باید با اجزای تشکیلدهنده آن آشنا شویم:
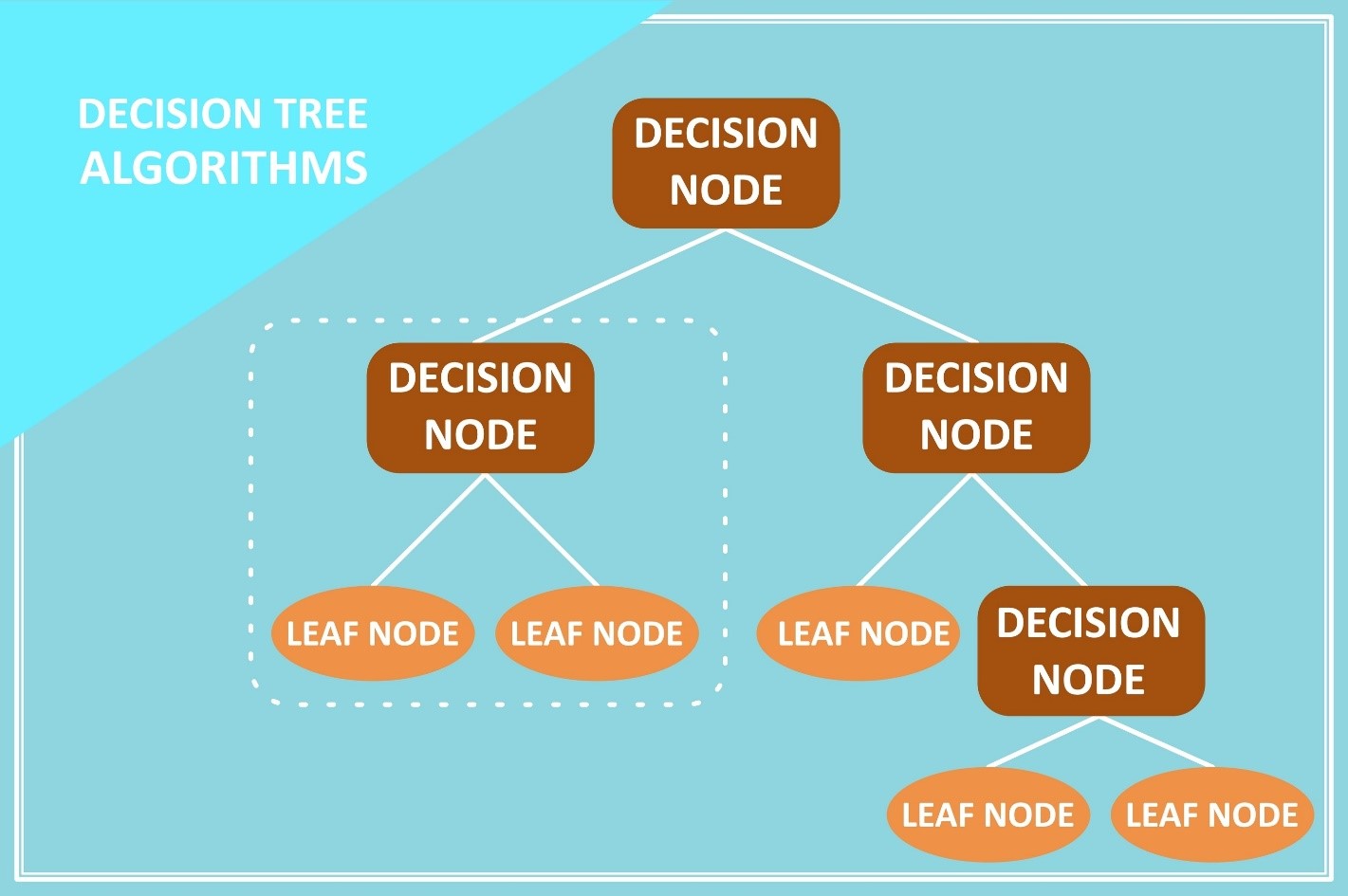
- گره ریشه (Root Node): نقطه شروع درخت که شامل تمام دادههای اولیه است. اولین و مهمترین سوال در اینجا پرسیده میشود (مثلاً در مثال بالا: “آیا هوا بارانی است؟”).
- گرههای تصمیم (Internal Nodes): گرههای میانی که در آنها یک شرط بررسی میشود و دادهها به دو یا چند شاخه تقسیم میشوند.
- شاخهها (Branches): فلشهایی که نتایج یک تصمیم (بله/خیر) را نشان میدهند و گرهها را به هم وصل میکنند.
- گرههای برگ (Leaf Nodes): گرههای پایانی که دیگر تقسیم نمیشوند. اینها حاوی پاسخ نهایی یا پیشبینی مدل هستند (مثلاً: کلاس “جنگل” یا کلاس “شهر”).
3- مکانیسم یادگیری: چگونه درخت ساخته میشود؟
چالش اصلی در ساخت درخت این است: کدام سوال را اول بپرسیم؟
آیا برای تشخیص نوع زمین، اول باید بپرسیم “ارتفاع چقدر است؟” یا بپرسیم “شاخص گیاهی (NDVI) چقدر است؟”
الگوریتم برای انتخاب بهترین سوال، تمام حالتها را امتحان میکند و سوالی را انتخاب میکند که دادهها را به خالصترین (Purest) شکل ممکن جدا کند. برای سنجش خلوص، از معیارهای ریاضی زیر استفاده میشود:
۱. آنتروپی (Entropy) و کسب اطلاعات (Information Gain)
- آنتروپی میزان بینظمی در دادههاست. اگر در یک سبد هم سیب باشد و هم پرتقال، آنتروپی بالاست. اگر فقط سیب باشد، آنتروپی صفر است.
- الگوریتم سوالی را انتخاب میکند که بیشترین کاهش در آنتروپی (بیشترین کسب اطلاعات) را ایجاد کند.
۲. شاخص جینی (Gini Impurity)
این معیار (که کمی سریعتر محاسبه میشود) احتمال این را میسنجد که اگر یک داده تصادفی را انتخاب کنیم، چقدر احتمال دارد آن را اشتباه طبقهبندی کنیم. هدف درخت، رساندن ناخالصی جینی به صفر است.
4- مزایا و معایب: چرا و کی استفاده کنیم؟
مزایا (چرا محبوب است؟)
- تفسیرپذیری عالی (White Box): برخلاف شبکههای عصبی که نمیدانیم چرا تصمیم گرفتند، در درخت تصمیم میتوانید مسیر را دنبال کنید و بگویید: «چون شیب زمین زیاد بود و پوشش گیاهی کم بود، سیستم اینجا را خطر لغزش تشخیص داد.» این ویژگی برای مدیران شهری و سیاستگذاران بسیار جذاب است.
- عدم نیاز به نرمالسازی: درخت تصمیم اهمیتی نمیدهد که یک داده بین ۰ تا ۱ است و دیگری بین ۱ تا ۱۰۰۰. (برخلاف SVM یا شبکههای عصبی).
- کار با دادههای کیفی: به راحتی با دادههای غیرعددی (مانند نوع خاک: رسی، شنی) کار میکند.
معایب (چرا خطرناک است؟)
- بیشبرازش (Overfitting): بزرگترین دشمن درخت تصمیم! اگر جلوی رشد درخت را نگیرید، آنقدر سوالات ریز و جزئی میپرسد که دادههای آموزشی را حفظ میکند و روی دادههای جدید به شدت خطا میدهد. (راه حل: هرس کردن درخت یا Pruning).
- ناپایداری: با تغییر کوچکی در دادههای ورودی، ممکن است ساختار کل درخت عوض شود.
5- کاربرد در GIS و سنجش از دور
درخت تصمیم به دلیل ماهیت سلسلهمراتبیاش، بسیار شبیه به روشهای کلاسیک طبقهبندی در GIS است:
- طبقهبندی پوشش اراضی (Based-Rule Classification):
بسیاری از متخصصان GIS به صورت دستی درخت تصمیم میسازند (مثلاً در ModelBuilder).
- اگر NDVI > 0.2 و ارتفاع < 1000 متر -> کشاورزی
- اگر NDVI < 0.1 و شیب < 5% -> آب
الگوریتم درخت تصمیم این بازهها (Thresholds) را به صورت خودکار و با دقت ریاضی پیدا میکند.
- ارزیابی تناسب اراضی (Site Selection):
برای مکانیابی دفن زباله یا توسعه شهری، درخت تصمیم میتواند قوانین سختگیرانه و منعطف را ترکیب کند تا بهترین مکانها را پیشنهاد دهد.
6- از درخت تا جنگل
از آنجا که یک درخت تصمیم واحد ممکن است خطا داشته باشد یا دچار بیشبرازش شود، دانشمندان داده راه حلی هوشمندانه ارائه دادند: جنگل تصادفی (Random Forest).
در این روش، صدها درخت تصمیم ساخته میشوند و رایگیری میکنند. اگر ۸۰ درخت بگویند “اینجا جنگل است” و ۲۰ درخت بگویند “مرتع است”، نظر اکثریت پذیرفته میشود.
7- نتیجهگیری
درخت تصمیم، الفبای یادگیری ماشین برای مسائل ساختاریافته است. سادگی، سرعت و از همه مهمتر شفافیت آن باعث شده تا با وجود روشهای جدیدتر، همچنان در صدر ابزارهای تحلیل داده باقی بماند. برای یک مشاور GIS که نیاز دارد دلایل فنی تحلیلهای خود را به کارفرما توضیح دهد، درخت تصمیم بهترین دوست است.
درباره نویسنده:
فاطمه جعفری نوبخت، متخصص برجسته و پژوهشگر حوزه مهندسی محیط زیست، با رویکردی نوین دانش کلاسیک این رشته را با فناوریهای پیشرفته هوش مصنوعی تلفیق کرده و به عنوان پیشگام در زمینه هوش مصنوعی مکانی (GeoAI) شناخته میشود. وی با تکیه بر مدرک کارشناسی ارشد مهندسی محیط زیست و درک عمیق از اکوسیستمها، تخصص خود را فراتر از روشهای سنتی گسترش داده و با ورود به دنیای دادهها، فعالیتهای حرفهای خود را بر کاربرد هوش مصنوعی در علوم محیط زیست متمرکز کرده است. او هماکنون به عنوان مشاور ارشد علوم مکانی در محیط زیست و منابع طبیعی، با استفاده از الگوریتمهای پیشرفته در پی راهکارهایی برای پایش دقیق، پیشبینی تغییرات اقلیمی و مدیریت بهینه منابع است. فاطمه جعفری با باور بنیادین به اینکه «مهمترین توجه انسانها باید به مقوله محیط زیست باشد»، تکنولوژی را ابزاری قدرتمند برای نجات زمین میداند و علاوه بر پروژههای استراتژیک، با برگزاری مستمر کارگاههای آموزشی در زمینه علوم مکانی و زمین، مشتاقانه به انتقال دانش و تربیت نسلی متخصص برای حفاظت از آینده محیط زیست میپردازد.





